
指南
如何抓取 Redfin:房产数据 Python 指南
简要说明:Redfin 公开了隐藏的 API 端点,这些端点可返回结构化的 JSON 房源列表,从而使完全跳过脆弱的 HTML 解析成为可能。本指南将指导您构建一个 Python 搜刮器,它可以提取租售数据、按位置搜索、通过 XML 网站地图监控新房源,并将干净的结果导出为 CSV 或 JSON。
Suciu Dan2 min read
Apr 27, 2026关于网页抓取、代理管理和数据提取的分步教程、最佳实践及实用指南。
简要说明:Redfin 公开了隐藏的 API 端点,这些端点可返回结构化的 JSON 房源列表,从而使完全跳过脆弱的 HTML 解析成为可能。本指南将指导您构建一个 Python 搜刮器,它可以提取租售数据、按位置搜索、通过 XML 网站地图监控新房源,并将干净的结果导出为 CSV 或 JSON。

简要说明:XPath 是一种查询语言,用于通过路径、属性或文本内容导航 HTML/XML 树。本指南涵盖 XPath 语法、轴和函数,然后展示了使用 lxml 和 Selenium 运行 Python scraers 的情况。您还将获得一份综合小抄和针对最常见 XPath 错误的故障排除部分。

简要说明:Scrapy-Playwright 可让你通过 Playwright 控制真实的 Chromium、Firefox 或 WebKit 浏览器,直接在 Scrapy spiders 中渲染 JavaScript 繁重的页面。本教程将指导你完成安装、配置、页面交互、AJAX 截取、反检测和生产就绪的项目结构,这样你就可以在不离开 Scrapy 生态系统的情况下抓取动态网站了。

使用 Python 结合 JavaScript 渲染、代理服务器、CSS 选择器和分页功能,抓取 Expedia 的酒店列表,然后对数据进行清理并导出为 CSV 格式。

借助 SERP 抓取 API,轻松从搜索引擎收集实时数据。轻松提升市场分析、SEO 及主题研究的效果。立即开始!

借助 Web Scraping API 经济高效的解决方案,高效抓取亚马逊数据。获取从商品到卖家资料的实时数据。立即注册!

简而言之:Scrapy 是一个完整的抓取框架,可在一个软件包中处理请求、解析和数据导出。Beautiful Soup 是一个轻量级解析库,可与 HTTP 客户端(如请求)配对使用。当你需要利用内置管道进行大规模并发抓取时,请选择 Scrapy。当你需要一个快速、最小化的设置来解析少量页面时,请选择 Beautiful Soup。

简要说明:Scrapy Splash 将 Scrapy 的快速抓取引擎与 Splash 无头浏览器配对使用,以渲染 JavaScript 较多的页面。本 Scrapy Splash 教程将指导你完成 Docker 设置、Scrapy 项目配置、SplashRequest 基础知识、用于滚动和点击的 Lua 脚本、代理集成,以及修复你将遇到的最常见错误。

简要说明:亚马逊产品页面包含大量有价值的数据(价格、评分、评论、ASIN),但可靠地提取这些数据需要的不仅仅是基本的 HTTP 请求。本指南将指导您使用 Requests 和 BeautifulSoup 构建 Python scraper,处理分页和反僵尸防御,导出为 CSV 或 JSON,并将结果输入 LLM 工作流。您还将了解何时使用刮擦 API 而不是推出自己的解决方案。

简要说明:职位搜索工具包括轻量级 API 服务和开源浏览器自动化,以及人工智能驱动的提取器和可视化无代码平台。本指南比较了 Google Jobs、Indeed、Monster、Upwork 和自由职业者市场上的最佳工作搜索工具,然后指导您通过重复数据删除、调度和反僵尸处理来构建可靠的管道,从而开始大规模收集干净的工作数据。

立即开始使用 WebScrapingAPI——终极网页抓取解决方案!实时采集数据,绕过反机器人系统,并享受专业支持。

简要说明:Cloudflare 通过对浏览器进行指纹识别、检查报头和分析行为信号来阻止 vanilla Selenium。本指南介绍了五种实用的绕过方法(未检测到的 ChromeDriver、Selenium Stealth、SeleniumBase UC 模式、验证码解码器集成和刮擦 API),并附有 Python 代码、比较表和故障排除运行手册,因此您可以根据自己的规模和预算选择合适的方法。

简要说明:没有官方的 Google SERP API,因此由第三方提供商来填补这一空白。价格从每千次搜索大约 0.30 美元到 15 美元不等,正确的选择取决于您的搜索量、预算以及需要提取的 SERP 功能。本指南对顶级提供商进行了并列比较,分解了规模化的真实成本,并为您提供了一个决策框架,以筛选出最适合您项目的 SERP API。

简要说明:Axios 通过代理路由请求,接受包含主机、端口和可选 auth 字段的代理对象。本指南介绍如何从头开始设置 Axios 代理配置:基本布线、认证代理、HTTPS 隧道、使用拦截器的轮换系统、通过 socks-proxy-agent 实现 SOCKS5 以及诊断常见错误。每个片段都是可复制粘贴的 Node.js 代码。

简而言之:Puppeteer 下载文件工作流程有四种形式:点击按钮,让 Chrome 浏览器写入你控制的文件夹;在页面内运行 fetch() 并将 base64 管道传回 Node;利用下载进度事件驱动 Chrome DevTools 协议;或者跳过浏览器,利用从 Puppeteer 会话中获取的 Cookie 通过 Axios 获取 URL。根据文件大小、身份验证和网站公开链接的方式进行选择。

简要说明:Node-Fetch 没有内置代理开关,因此您需要通过代理选项将 HTTP、HTTPS 或 SOCKS5 代理接入请求。本指南从头到尾介绍了如何在 Node-Fetch 中使用代理:经过验证的 HTTP 和 HTTPS 代理、SOCKS5、轮换、重试、TLS 边缘情况、故障排除以及 Node 18+ 原生获取的现代 undici 路由。

简而言之:用 Python 对 JavaScript 表格进行网络刮擦很少需要无头浏览器。打开 DevTools,找到与网格融为一体的 JSON 端点,用请求重放它,对它进行分页,只有当网络调用被签名、加密或以其他方式密封时,才返回 Playwright。

简要说明:本指南展示了如何在 Golang 中从头到尾地刮擦 HTML 表格:在 Colly、goquery 和 golang.org/x/net/html 之间进行选择,以正确的 <tbody> 为目标,将行建模为类型化结构,并导出干净的 JSON 和 CSV。你还能获得分页、反阻塞和 JavaScript 渲染的表格模式。
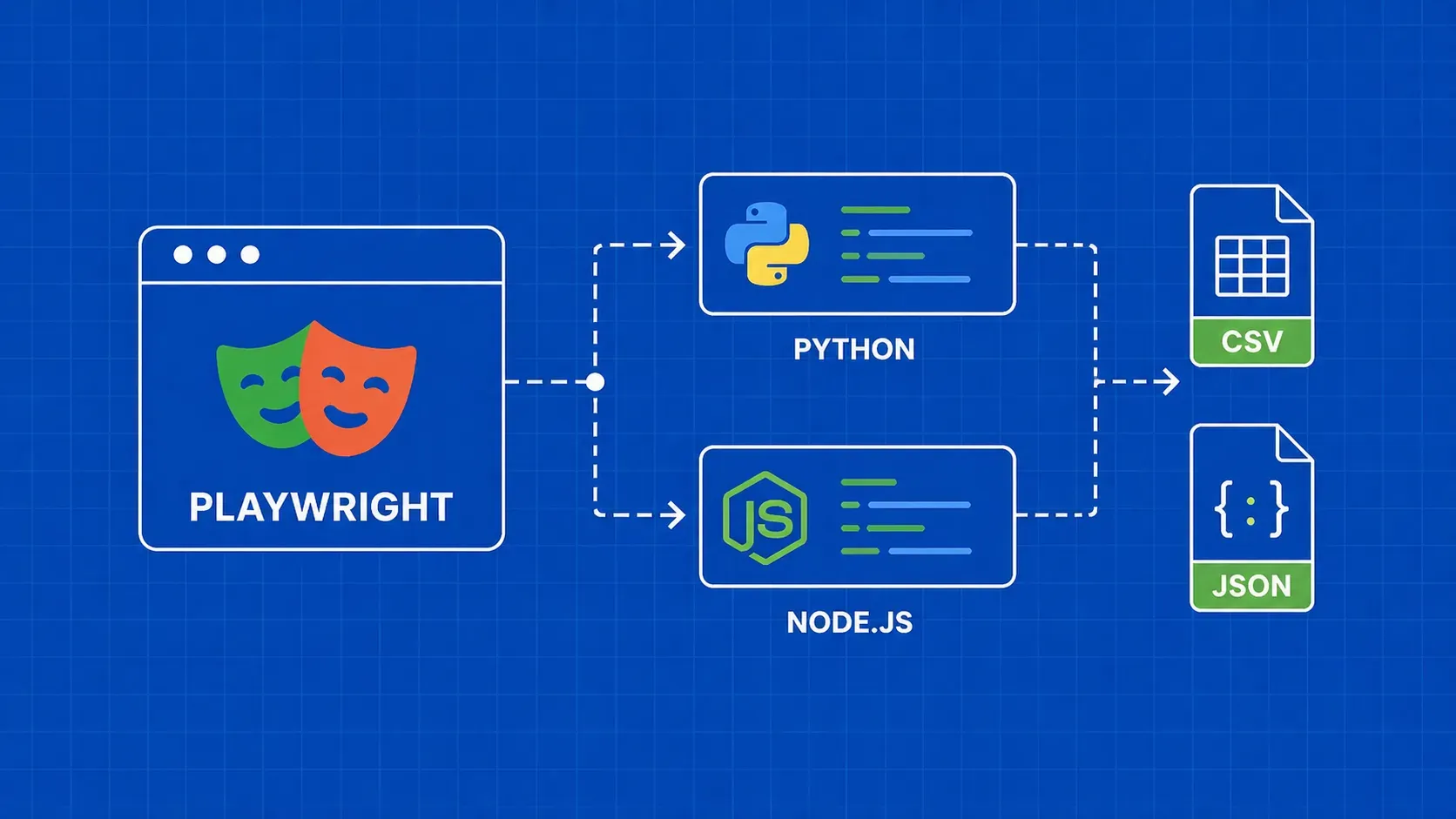
简要说明:Playwright 为您提供了全面的浏览器自动化功能,可用于刮擦 JavaScript 繁重的网站,并为 Python 和 Node.js 提供一流的支持。本指南将指导您完成安装、元素提取、代理配置、反检测、分页、图片下载以及将数据导出为 CSV 或 JSON 等操作,并提供两种语言的并行代码示例。

简要说明:要想知道如何从 Google 地图中抓取评论,有三种方法:旋转代理后的 DIY Selenium 抓取器、带有渲染说明的抓取 API 或返回解析 JSON 的结构化地图评论 API。本指南用 Python 演示了这三种方法,包括可复制粘贴的代码、分页模式、防拦截策略,以及将原始评论转化为企业可实际使用的内容的最后清理步骤。

使用 Python 和 wget 实现网页抓取和文件下载的自动化。学习如何利用这些工具收集数据并节省时间。

掌握网络爬虫技巧,避免被封禁!遵循遵守服务条款、使用代理服务器以及规避IP封禁的建议。以符合道德和法律的方式提取数据。

简要说明:本指南从头到尾介绍了如何在 Python Requests 中使用代理:一个有效的代理字典、经过验证的 URL、环境变量、会话重用、不泄漏 DNS 的 SOCKS5 以及带有重试和断路器的轮换池。到最后,你就会知道什么时候托管 API 比 DIY 池更有价值。

了解如何使用 Node.js 配合我们的 API 抓取 Google 地图的地点结果:分步指南、专业抓取工具的优势等。轻松获取 data_id、坐标以及构建数据参数。

简而言之:当您需要从您已经信任的 HTML 中提取简短、可预测的文本模式(价格、SKU、电子邮件、日期)时,使用 regex 进行 Web scraping 就会大显身手。将 Python 的 re 模块与 Beautiful Soup 搭配使用,将模式范围扩大到解析的节点而不是原始标记,让 regex 远离完整的 HTML 树解析。本指南将介绍标题和价格搜索器的工作原理、高级 regex 功能,以及真正的搜索器在生产中会遇到的陷阱。

利用专业的网页抓取技术,充分挖掘Twitter数据。学习如何抓取Twitter数据以进行情绪分析、市场营销和商业情报分析。本指南全面介绍了如何使用TypeScript进行操作。

简要说明:要在 C# 中使用 HttpClient 代理,只需创建一个 WebProxy,将其附加到 HttpClientHandler(或 SocketsHttpHandler),然后将该处理程序传递给 HttpClient 构造函数。在生产中,将手动循环换成 IHttpClientFactory,为经过验证的代理添加 NetworkCredential,并使用 Polly 将调用包裹在重试中,这样死 IP 就不会让你的工作程序宕机。

本教程将演示如何使用 Python 进行网页爬取。网页爬取是一种强大的方法,通过定位一个或多个域名的所有 URL 来从网络上收集数据。

简而言之:只需使用一行 pandas.read_html 命令,就能刮擦大部分 HTML 表格。当表格是分页的、JavaScript 渲染的或有合并表头时,请切换到 Requests + BeautifulSoup 或像 Playwright 这样的无头浏览器。本指南为您提供了决策矩阵、三种方法的工作代码,以及将刮擦行转化为管道就绪数据的清理步骤。

简而言之:Cheerio 是轻量级 HTML 解析器;Puppeteer 驱动真正的 Chromium 浏览器。当数据已经存在于原始 HTML 中时,使用 Cheerio;当 JavaScript 渲染数据时,使用 Puppeteer;当每次访问需要提取大量字段的 JS 页面时,将它们结合起来使用。

简而言之:如果你正在研究如何干净利落地抓取 Realtor.com,那么有三件事最为重要:稳定的选择器(能经受住散列类名称的考验)、能经受住 Realtor 反僵尸堆栈的请求层,以及能同时浏览列表页和详情页的代码。本指南是完整的 Python 构建,包含反僵尸策略和 LLM 就绪导出。

简要说明:本指南将介绍如何使用 Python 从头到尾对 Booking.com 进行网络搜刮:提取搜索列表、酒店页面、每晚价格和客人评论。您将获得两种互补方法:一种是用于 JS 渲染页面的 Selenium Wire 工作流,另一种是直接调用 Booking.com 内部 /dml/graphql 端点的更快路径,此外还有反阻塞播放器、货币处理和解决约 1,000 个结果分页上限的方法。

通过这11条实用建议,您将学会如何进行网页抓取而不被列入黑名单。从此再也不会出现错误提示了!

简要说明:Idealista 是西班牙、意大利和葡萄牙最大的房产交易市场,但它背后有一个严密的反僵尸堆栈,可以快速阻止天真的刮擦程序。本指南将指导您如何使用 Python 从 Idealista 端到端搜刮数据,包括网站映射、Selenium 与 undetected-chromedriver、DataDome 处理、代理轮换和干净的导出,以及竞争对手通常跳过的生产加固。

简要说明:本指南将指导您使用 Python 构建一个完整的 Yelp 搜索工具,包括搜索结果、企业详细信息和评论,并提供工作代码。您还将学习如何处理反僵尸保护、将数据导出为 CSV 或 JSON,以及如何将搜索到的评论输入 LLM 进行情感分析,这是其他 Yelp 搜索教程所不具备的。

了解如何使用 Node.js 和我们的 API 从 Google 购物中抓取附近的卖家信息。借助我们专业的网页抓取工具,快速轻松地提取有价值的数据。

简而言之:在快速、确定性的 Puppeteer 提交表单脚本中使用 page.locator(selector).fill(value),在页面观察真实按键(自动完成、反机器人、实时验证)时使用 page.type()。通过点击按钮、按回车键或调用 form.requestSubmit() 提交,并始终等待具体的成功信号,而不是固定的超时。

简要说明:Pyppeteer 是 Puppeteer 的非官方 Python 移植版本,仍可用于从 asyncio 驱动真正的 Chromium。在本指南中,您将安装它,使用 asyncio.run 和 try/finally 编写 Pyppeteer 现代 Web 刮擦程序,处理等待、表单、截图、无限滚动、cookie 和代理,并了解何时迁移到 Playwright、Selenium 或托管刮擦 API。

简要说明:本指南介绍了如何使用 Python 端到端网络搜刮沃尔玛产品数据,从解析隐藏的 __NEXT_DATA__ JSON 到使用代理、重试和异步获取进行扩展。它还诚实地说明了什么时候托管的搜刮 API 能胜过 DIY。

了解使用 Node.js 抓取 Google 购物产品规格的分步指南。通过本教程提升您的网页抓取技能。

简而言之:Cloudflare 通过将 TLS 指纹识别、JavaScript 挑战、行为分析和 Turnstile 验证码层层叠加到一个综合信任分数中来阻止刮擦。要可靠地绕过 Cloudflare,您需要同时匹配每一层。本指南涵盖了检测堆栈,比较了四种实用工具(Nodriver、SeleniumBase UC、Camoufox、curl-impersonate),并介绍了代理策略、会话持久性、错误排除和生产扩展。

通过我们的快速入门指南,了解如何像专家一样使用 Web Stealth Proxy。获取分步操作指南,提升您的代理使用技巧,将您的在线隐私保护提升到新高度。立即开始!

TL;DR:这是一本关于如何用 Python 搜刮 YouTube 的 2026 操作手册。你将使用决策矩阵选择正确的方法(Data API v3、yt-dlp、隐藏的 /youtubei/v1/ 端点或托管的 scraper),然后运行代码来处理视频元数据、评论、频道、搜索、Shorts 和转录,其中还有一个关于代理、标头和 429 回退的制作部分,这样你就不会被屏蔽了。

简要说明:本指南展示了如何在 Python 中端到端轮换代理:选择正确的代理类型,构建并验证一个代理池,然后使用 itertools.cycle 按顺序轮换,使用 random.choice 随机轮换,或使用 aiohttp 异步轮换。我们还将 IP 轮换与 User-Agent 轮换配对使用,并添加状态感知重试,这样单个不良代理就不会扼杀你的搜刮。

简而言之:Python 无头浏览器可让您渲染 JavaScript、点击 SPA,以及抓取普通 HTTP 客户端无法访问的网站。Selenium 是最安全的默认设置,Playwright 是新代码的现代选择,Pyppeteer 和 Splash 仍有利基用途,而托管浏览器 API 则是在反僵尸防御或规模开始吃紧时的选择。

了解用于解析 HTML 和 XML 的热门 Ruby 库(包括 Nokogiri、REXML、Ox、Hpricot 和 Oga)的优缺点,从而找到最适合您需求的方案。


您是否想过使用 JavaScript 从网页上的 HTML 表格中提取数据?在本篇文章中,您将了解到如何结合使用 cheerio 库和 Node.js,轻松地从任何网站的表格中抓取数据。

简要说明:Jsoup 是 Java 中用于 HTML 解析的默认库。本指南介绍了整个生命周期(Maven 设置、加载文档、CSS 选择器、DOM 遍历、提取、修改和序列化),以及可运行的刮擦项目、错误处理、分页和将您推向无头浏览器或刮擦 API 的限制。


简而言之:要以 Python 方式从 HTML 中提取文本,请使用真正的解析器(BeautifulSoup、lxml.html 或 html-text)解析标记,去除脚本、样式和网站 Chrome 浏览器,然后在保存前对空白和 Unicode 进行规范化处理。本指南对主要库进行了比较,修正了常见的清理陷阱,最后提供了一个可运行的爬虫,可写入 JSONL 和每页的 .txt 文件。

TL;DR:这是一本有见地的、端到端的指南,介绍如何在 2026 年使用 Scrapy 进行网页刮擦。你将安装 Scrapy、在外壳中建立选择器原型、构建多页面电子商务蜘蛛、使用 Item Loaders 清理项目、持久化到数据库、加固设置以防封禁,以及为 JavaScript 渲染的页面安装 Scrapy-Playwright。

您在使用 Scrapy 抓取动态网站时遇到困难了吗?本文将探讨几种处理 JavaScript 渲染的解决方案。了解如何使用 Splash 和 Selenium 等插件,让您的 Scrapy 项目更上一层楼。

简而言之:Axios 设置了五层标头:每请求配置、全局默认值、axios.create() 实例、请求和响应拦截器以及响应本身。本指南使用可运行的 v1 代码段对每一层进行了说明,然后修复了咬伤每个人的四个 bug:多部分边界、CORS cookie、自签名证书和标头封装。

开发人员正在使用网络抓取器来获取各种数据。让我们向你展示如何使用 JavaScript 构建自己的 Web Scraping。

如果你有 Ruby、一堆实用的 gems 以及几个小时的时间,能做出什么?答案是——一个相当不错的网页爬虫。以下是分步指南:
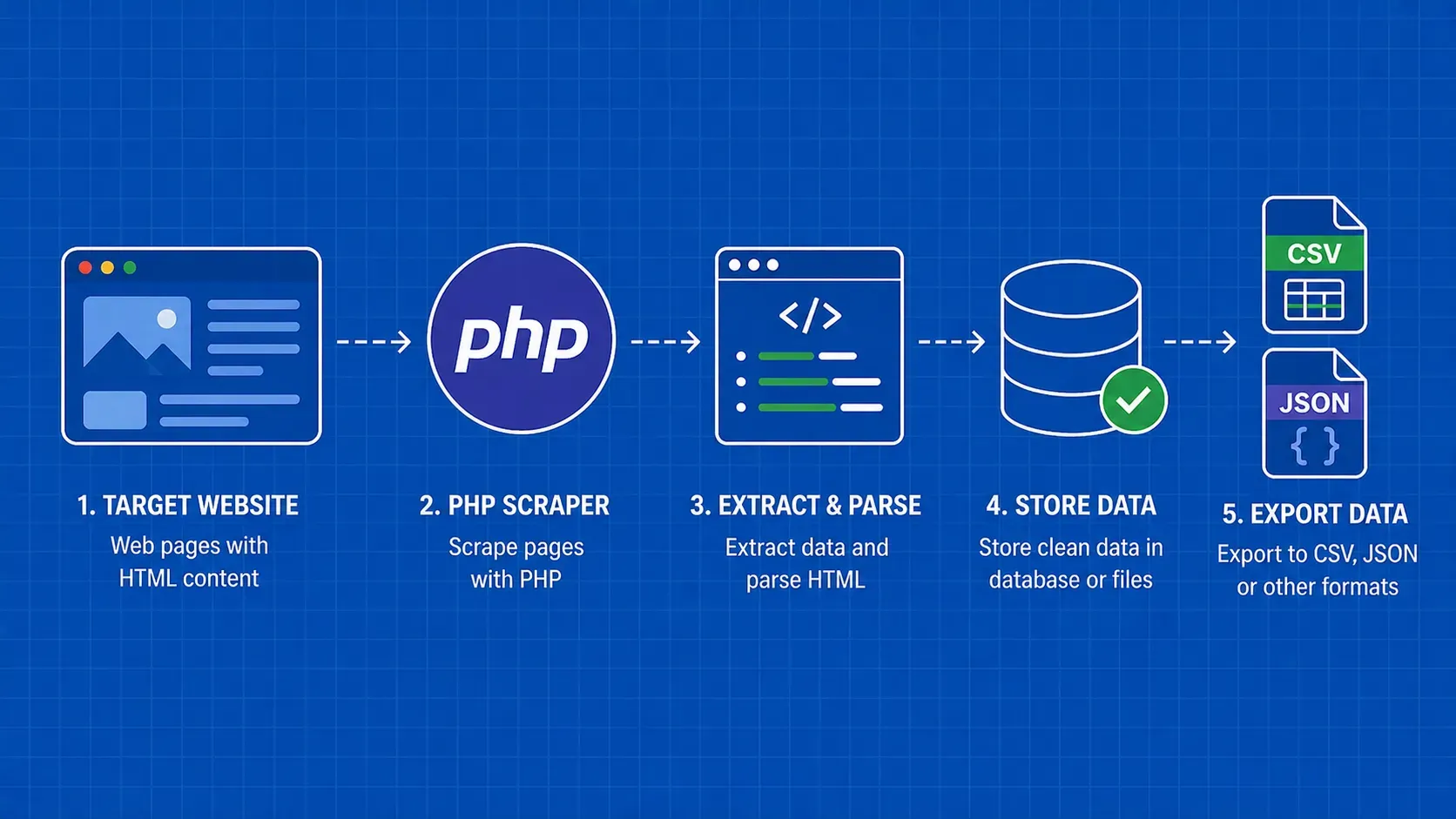
简而言之:由于内置了 cURL 和 DOMDocument 等扩展,再加上包括 Guzzle、Symfony DomCrawler 和用于无头浏览的 Symfony Panther 在内的丰富的 Composer 生态系统,PHP 完全有能力胜任 Web 搜索。本指南将指导您完成整个工作流程:获取页面、解析 HTML、将结果存储到 CSV/JSON/MySQL、处理错误以及避免阻塞。
使用 Cheerio,您只需几分钟即可开始收集数据。操作简单,无需学习。

简要说明:这本 XPath 小抄涵盖了网络搜刮实际需要的语法、谓词、轴和函数,还有 CSS 到 XPath 转换表和可运行的 Puppeteer 和 Scrapy 示例。下次当你依赖的网站上的 CSS 选择器悄无声息地崩溃时,你可以将它作为桌面参考。

阅读本文,了解有关代理列表的宝贵见解、代理服务器列表的优势、最佳的付费代理API工具、如何选择代理工具等更多内容。

简而言之:在 Python 中使用 cURL 有三种合理的方法:使用子进程 shell out 到 curl 二进制文件,通过 PycURL 绑定到 libcurl,或者完全跳过 curl 而使用 Requests 库。了解如何在 Python 中很好地使用 cURL 意味着对这三种方法都了如指掌。本指南将为你提供这三种方法的可运行示例、curl-flag-Python 转换表和决策矩阵,以便你第一次就能选择正确的工具。

了解如何使用新发布的 node-fetch 直接从 Node.js 发起 HTTP 请求。node-fetch 相当于 JavaScript 中的 fetch API
探索2022年最优秀的Python HTTP客户端,用不到X行代码就能搭建自己的网页爬虫。
了解如何在 Python 中使用 CURL 进行网页抓取,并仅需几分钟即可构建一个简单的网页抓取应用程序。

你想了解网络爬虫的重要性,以及它如何助你超越竞争对手吗?如果是的话,那你来对地方了!

当您在上网时想要隐藏自己的IP地址时,Web代理将为您排忧解难。Node Unblocker 就是这样一款代理服务器。本文将为您详细介绍它。

简要说明:Scraping LinkedIn 意味着要绕过咄咄逼人的认证墙、行为跟踪和 TLS 指纹识别。本指南为您提供了按页面类型划分的方法决策树,适用于工作、个人资料和公司的 Python 工作模式(必要时使用隐藏 API、JSON-LD 和 Selenium),以及 2026 年的综合防拦截清单。

简要说明:2026 年的 12 款最佳免费网络搜刮工具分为四类:管理 API(免费积分)、开源框架、无代码浏览器扩展和人工智能提取器。首先根据使用情况(一次性搜索与计划管道)进行选择,然后根据技能水平进行选择。大多数免费层级包括评估,而非生产;一旦你的成功率低于 90%,或者你在区块上花费的时间多于数据,就该升级到付费 API 了。

让我们来看看雅虎财经API,以及那些正在兴起并不断改进客户财务数据收集功能的雅虎替代方案

简要说明:网络搜索合法吗?通常是,但有注意事项。合法性取决于数据类型、访问路径、所涉及的司法管辖区以及你对输出结果的处理方式。本指南将为您提供直接判断、5 分钟的预搜索框架、重要案例,以及可在发布前运行的检查清单。


了解动态IP地址的方方面面,包括其工作原理以及为何对软件开发人员至关重要。本指南适合初学者,全面介绍了该主题,让任何人都能轻松理解。

探索9款顶尖的Google图片搜索API工具,实现高效的图片抓取。了解如何利用这些强大的API优化图片搜索,并提升数据采集效率。

简而言之:糟糕的代理服务器代价高昂。它们会消耗带宽、触发封禁,并悄无声息地破坏你的 scraper 所依赖的数据。本指南介绍了如何使用 ping、curl、在线检查器、IP 数据库和一个可重复使用的 Python 脚本来测试代理的五个健康信号(连接性、出口 IP、速度、匿名性和声誉),您可以将其放入您的 CI 管道中。

网络爬虫是从各类网站中提取数据的绝佳方式,为了确保获取正确的数据,通常会使用像Cheerio这样的工具。

本文深入介绍了Apiasp.net核心网络爬虫技术。您不仅能全面了解这一主题,还能探索最适合您网络爬虫需求的工具——WebScrapingAPI。

以下是市场上值得信赖的最佳网页抓取工具清单,以及关于这些工具的全面指南。您无需再费心寻找了。

深入了解 Web Scraper Tool 的方方面面,包括它的定义及其功能。此外,我还列出了若干可供替代的工具供您尝试。

HTTP Cookie 是现代网站浏览体验的重要组成部分。了解其重要性、用途,以及它可能对终端用户造成的各种危害。

数据抓取应用程序会从网络中提取有价值的信息,并将其保存到计算机系统的本地文件中。

自动化网页抓取是一种可靠的技术,可确保您从多个网站获取有价值的结构化数据,从而做出经过深思熟虑的数据驱动型决策。

了解Scrapebox的五大替代方案,以及哪款网络爬虫工具脱颖而出。



简而言之:Puppeteer 是快速实现 Chromium 自动化的好帮手,但它的单一浏览器锁定、资源繁重的扩展性和零内置反僵尸支持等问题,促使许多团队转向其他替代方案。本指南按使用案例(刮擦、E2E 测试、跨浏览器 QA、移动)细分了最强大的 Puppeteer 替代品,为您提供了并排比较表,最后还提供了一个决策框架,让您无需反复试验就能选择合适的工具。

如今市面上有众多网页抓取工具,每个品牌在功能、优缺点方面都各具特色。本文将为您介绍7款最值得推荐的网页抓取工具,以满足您的抓取需求。


Charles 代理是当今最常用的调试工具之一。让我们来探讨它的优缺点,并了解多种替代方案

Import.io 是一款性能出色的工具,许多企业都用它来抓取电商网站数据。不过,如果你对其缺点感到不满意,以下是八款最优秀的 Import.io 替代方案。

使用网页抓取工具是从网络上收集所需数据的最佳方法之一。本文将向您介绍具体操作方法,并推荐一些实用工具。

作为一名开发者,你必须了解最优秀的 PhantomJS 替代方案。阅读这篇博客,了解前 7 大选择,并为自己挑选最合适的一款。

正在寻找 Scrapy 的替代方案吗?以下是 7 款顶尖替代工具,它们将满足您的网页抓取需求。

您可能已经使用 Web Scraper 多年了。然而,您可能会意识到,为了满足各种需求,您可能需要一款 Web Scraper 的替代方案。

您是否正在为数据提取项目寻找 WebHarvy 的替代方案?请阅读下文,了解目前可用的 7 大替代方案。

Niche Scraper 是一款广受欢迎的产品抓取工具。然而,出于各种原因,可能还有比它更好的解决方案。因此,不妨考虑使用以下这 5 款最佳的 Niche Scraper 替代工具之一。
简而言之:Wget 虽然可靠,但已经老化。如果需要并行下载,可以使用 aria2。如果需要广泛的协议覆盖范围和脚本,curl 是首选。想要更友好的 API 测试工作流程?HTTPie(或它的 Rust 兄弟 xh)就非常适合。如果你想要最接近的升级路径,wget2 会添加 HTTP/2、多线程和插件系统,同时保留你已经熟悉的命令模式。

你可能已经使用 Node-Fetch 多年了。然而,你可能会意识到,为了满足各种需求,你可能需要一个 Node-Fetch 的替代方案。

你是否一直在使用 Fetch?如果是的话,你一定要读读这篇博文,因为我们将介绍 5 款出色的 Fetch 替代方案,它们将彻底改变你的开发体验。

许多数据科学从业者都使用 R 语言进行网页抓取。本文将介绍使用 R 语言进行网页抓取的相关信息、其优势以及更多相关内容。


本文将对市面上主流的产品搜索工具进行全面分析,并探讨为何 ProfitScraper 可能并非您的理想选择。我们将从优缺点、定价及最终结论等方面,根据所有提及的评估标准,为您揭晓哪款工具脱颖而出。

这是一份关于使用 Elixir 进行网页抓取的完整指南。了解如何使用这种最适合并发编程的语言之一来构建网页抓取工具。

Rust 是一种运行速度快且内存利用率高的编程语言。但它在处理网页抓取方面表现如何呢?请阅读这篇适合初学者的指南,了解如何使用它来构建一个基础的网页抓取工具。

这是一份关于如何使用 Go 语言进行网页抓取的完整指南。您将学习如何利用 Go 语言强大的并发能力构建高效的网页抓取工具。

您是否已经厌倦了使用 Octoparse 网络爬虫工具多日,正在寻找 Octoparse 的替代方案?那么请阅读这篇文章,了解十大最佳 Octoparse 替代方案。

这是一份关于如何使用 C# 进行网页抓取的完整指南。了解如何使用 C# 构建一个快速且高度可扩展的网页抓取工具。

简而言之:2026 年最好的 Node.js Web 搜刮工具分为两大阵营:HTTP 客户端(如用于静态页面的 Axios 和 Superagent)和无头浏览器(如用于 JavaScript 繁重网站的 Puppeteer 和 Playwright)。根据工作流而非受欢迎程度进行选择,一旦反僵尸防御或规模开始占用你的工程时间,就将渲染卸载到托管的刮削 API。

对市面上排名前7的ProxyScrape替代方案进行详细对比,看看哪款网页爬虫脱颖而出!

许多人高估了这类库的必要性。因此,你可能会考虑使用 Axios 的替代方案。

厌倦了将数百甚至数千个网址粘贴到网页抓取工具中吗?其实还有更简单的方法:自己动手制作一个爬虫!具体方法如下:

对于新产品来说,定价往往令人头疼。不过,有一个解决办法:从电商巨头那里抓取数据,并根据清晰的数据来定价。
简要说明:Puppeteer 可让你在 Node.js 中完全控制一个无头 Chrome 浏览器实例,使其成为刮削 JavaScript 渲染页面的首选工具。本指南将指导你完成安装、基于选择器的提取、无限滚动、表单登录、请求拦截、隐身插件、结构化数据导出和 Docker 部署,这样你就可以从一个玩具脚本变成一个生产级的搜刮器。

简要说明:这篇 BeautifulSoup 教程将引导您完成一个完整的 Python scraper,从 pip 安装到一个加固的脚本,该脚本可以分页浏览 Hacker News、导出为 CSV 和 JSON,并保持足够的礼貌以免被屏蔽。每个片段都可运行,我们还指出了 BeautifulSoup 是错误工具的确切时刻。


简要说明:Selenium 可让您通过 Python 代码驱动真实浏览器,从而刮擦 JavaScript 繁重的网站。本教程将指导您完成每个阶段的工作:安装 Selenium、配置 Chrome 浏览器、定位元素并与之交互、处理等待和分页、导出干净的数据,以及使用代理、Selenium Grid 和基于 API 的替代方法扩展您的 scraper。

C++ 的应用场景非常广泛,但你见过用 C++ 实现的网页爬虫吗?这里就有一款,还附带了一个教程,教你如何自己动手制作。

为从同一个网站抓取数百个页面而制作URL列表,可能会是一项繁琐的工作。幸运的是,你可以通过使用网站地图来避免这一麻烦。具体方法如下!

如果您对网络刮擦工具感兴趣,并想要一个能从互联网上提取各种数据的解决方案,那您就来对地方了!


学习如何使用 Python 构建自己的网络搜刮器,因为网络搜刮和网络搜刮器在过去十年中大受欢迎。