
网络爬虫技术
cURL 中的 HTTP 响应头:每个标记、技巧和脚本配方
简要说明:cURL 默认隐藏响应头信息。使用 -i 可以看到响应头和正文,使用 -I 可以看到 HEAD 请求只返回响应头,使用 -v 可以看到完整的请求/响应调试,使用 -D 可以将响应头保存到文件中。对于现代脚本,cURL 7.83+ 允许提取单个头信息,或使用 -w write-out 选项将所有头信息转存为 JSON 格式。
Suciu Dan3 min read
Apr 29, 2026深入探讨爬取、解析、反机器人系统背后的科学原理,以及大规模网络数据提取所面临的工程挑战。
简要说明:cURL 默认隐藏响应头信息。使用 -i 可以看到响应头和正文,使用 -I 可以看到 HEAD 请求只返回响应头,使用 -v 可以看到完整的请求/响应调试,使用 -D 可以将响应头保存到文件中。对于现代脚本,cURL 7.83+ 允许提取单个头信息,或使用 -w write-out 选项将所有头信息转存为 JSON 格式。

简要说明:无头浏览器是一种网络浏览器,运行时没有可见的图形界面,完全由代码或命令行指令控制。开发人员将无头浏览器用于自动测试、网络扫描、性能监控,并越来越多地用于支持人工智能代理。本指南将介绍无头浏览器的内部工作原理、何时选择无头浏览器而非普通浏览器,以及哪些框架值得你花时间研究。

简要说明:Scrapy 是一个高速异步抓取框架,用于大规模从静态页面中提取结构化数据。Selenium 可自动运行真实浏览器并处理 JavaScript 繁重的网站,但资源成本要高得多。大多数生产型抓取项目都会受益于了解何时使用每种方法,或何时将它们结合起来使用。
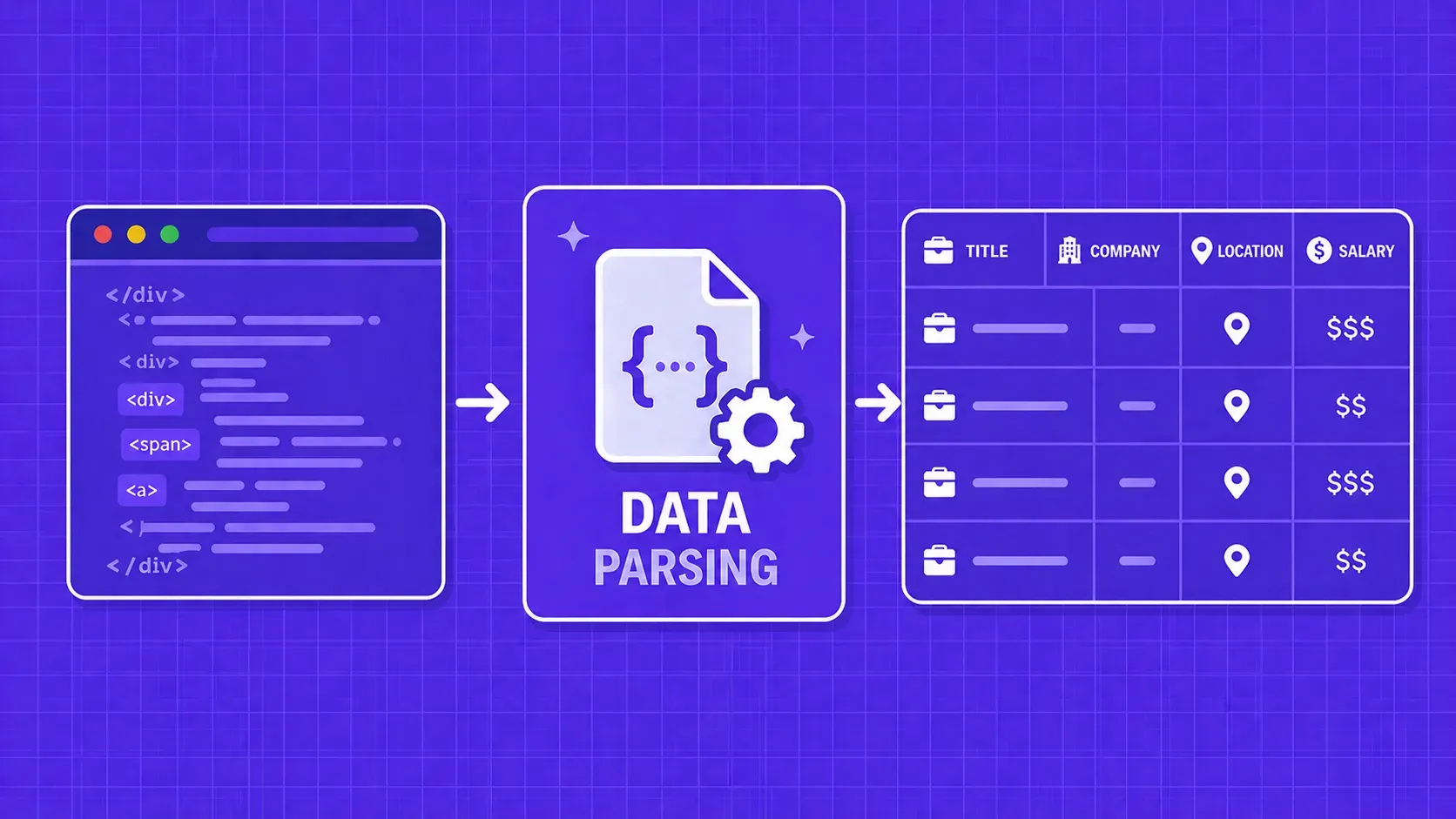
简要说明:数据解析将原始内容(HTML、JSON、XML、PDF)转换为代码可以实际使用的结构化字段。本指南将逐步介绍数据解析的工作原理,比较主要的技术和库,并为您提供一个实用的框架,帮助您决定是构建还是购买解析层。

简要说明:浏览器自动化是指通过代码驱动真实或无头 Web 浏览器,使其代表您点击、键入、导航和读取页面。本指南将解释什么是浏览器自动化,比较 Selenium、Playwright、Puppeteer 和 Cypress,并说明何时不需要使用完整浏览器。

简要说明:网络搜刮从公共网页中收集原始数据。数据挖掘分析结构化数据,以显示模式、预测和细分。它们是同一生命周期中的不同阶段,大多数生产系统都将它们结合在一个 "先搜刮,后规范化,再挖掘 "的流程中。

简要说明:最好的网络刮擦课程取决于你的语言、水平和目标用例。本指南比较了 Udemy、Coursera、DataCamp 和 Packt 的五种付费课程,指出了官方文档等免费补充内容,并介绍了如何从完成课程过渡到运行生产型刮擦程序。

简要说明:网络搜索项目在代码失败之前,其规划早已失败。这十个刮擦问题将引导您了解合法性、API 替代方案、反僵尸防御、成本、刷新频率、数据质量和管理,以便您确定工作范围、选择正确的堆栈,并避免在生产中悄然扼杀刮擦程序的失败模式。

简要说明:反侦测浏览器可让您运行多个独立的浏览器配置文件,每个配置文件都有唯一的指纹,因此平台无法链接您的账户。本指南从指纹质量、自动化支持、价格和代理集成等方面对 2026 年 15 款最佳反侦测浏览器进行了排名。我们还介绍了这些工具的实际工作原理,什么时候使用搜索 API 更明智,以及在每种使用情况下应搭配哪种代理类型。

简要说明:什么是 ISP 代理?它们是托管在数据中心的静态住宅 IP。检测系统看到的是住宅 ASN,而你得到的是数据中心吞吐量。当会话、账户绑定和可预测的每个 IP 定价比原始地理覆盖范围更重要时,它们就是最佳选择。

简而言之:HTTP 头信息通常是你的刮擦程序收到 403 而你的浏览器却能正常加载相同 URL 的原因。本指南介绍了反僵尸系统实际上会检查哪些标头,如何从 DevTools 中捕获真实浏览器的标头集,如何在 Python 和 Node.js 中正确发送和旋转标头,以及何时手动调整将不再奏效,而使用受管刮擦 API 才是更好的选择。

简而言之:2026 年最好的轮播住宅代理并不是拥有最大广告牌池规模的代理。它们在会话控制、地理定位、道德采购和按 GB 计算的经济性等方面都能真正匹配您搜索的目标。本指南为您提供了一个供应商中立的评估框架、12 家供应商的对比表和使用案例图,这样您就可以在使用信用卡之前筛选出两三家供应商。
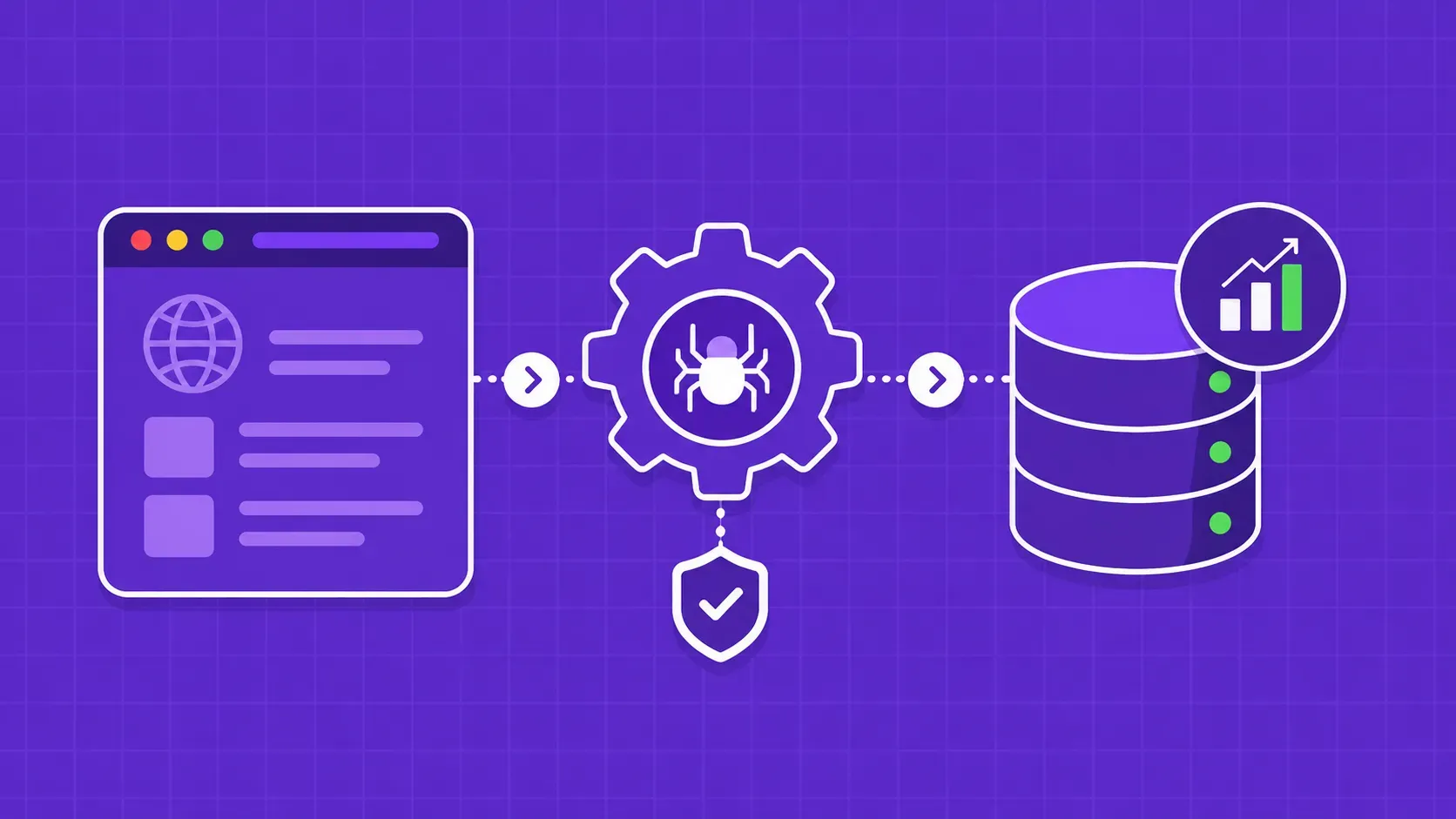
简要说明:Node-unblocker 将 Express 应用程序变成了一个 URL 前缀 HTTP 代理,你可以在上面进行黑客攻击。这篇网络搜刮节点解锁指南介绍了如何安装、连接请求和响应中间件、轮换实例、在 Docker 或 Heroku 上部署,以及如何识别托管搜刮 API 才是更明智的选择。

TL;DR:那么什么是旋转代理呢?代理服务器会为来自管理池的每个请求分配不同的 IP,这就是搜刮者如何绕过每个 IP 的速率限制、验证码和地理过滤器的原因。本指南介绍了旋转的工作原理、四种池类型、三种语言的设置代码以及如何选择提供商。


简要说明:python 网络爬虫可以自动完成在网站上跟踪链接以发现和收集内容的繁琐工作。本指南将指导您使用请求和 BeautifulSoup 从头开始构建爬虫,然后再使用 Scrapy 进行并发爬行、项目管道和结构化数据导出。您还将学习如何负责任地抓取、旋转代理以避免阻塞,以及如何处理 JavaScript 渲染的页面。

如果你喜欢网页设计,你可能对JavaScript略知一二,但你是否想过它对网页抓取有何影响?下面就来详细说明一下

虽然没有两套API是完全相同的,但为了提高效率,大多数API都遵循某种架构风格。以下是5种最常见的架构风格及其作用:


代理选择是任何网络爬虫项目中的关键步骤。今天,我们将对比专用IP和共享IP,并为您推荐一些服务商。

如果说网络爬虫是引擎,那么代理就是燃料。若想获得最佳效果,请选用反向连接住宅代理。以下是7种选择:


代理服务器是网络爬虫不可或缺的工具。了解移动代理如何助力您的爬虫项目,以及哪些是网上最优秀的代理服务提供商。


在选择一款能为您的业务或项目赋能的数据提取工具之前,您需要了解哪些信息?点击此处了解详情。

简而言之:现代阻塞发生在四个层面:网络、请求签名、浏览器和行为。首先使用状态代码和挑战页面对该层进行诊断,然后通过旋转式住宅代理、浏览器级标头、TLS 冒充、隐身浏览器和类人计时的正确组合进行修复。当流量或反僵尸技术的复杂性导致 DIY 不经济时,可将请求层卸载到托管 API。

在进行网页抓取的过程中,您可能会遇到一些障碍。请阅读本指南,了解如何通过IP轮换来解决抓取工具被封禁的问题。

如何以简单、快速且高效的方式获取数据?当然是网络爬虫。但这有哪些好处呢?点击此处了解详情。
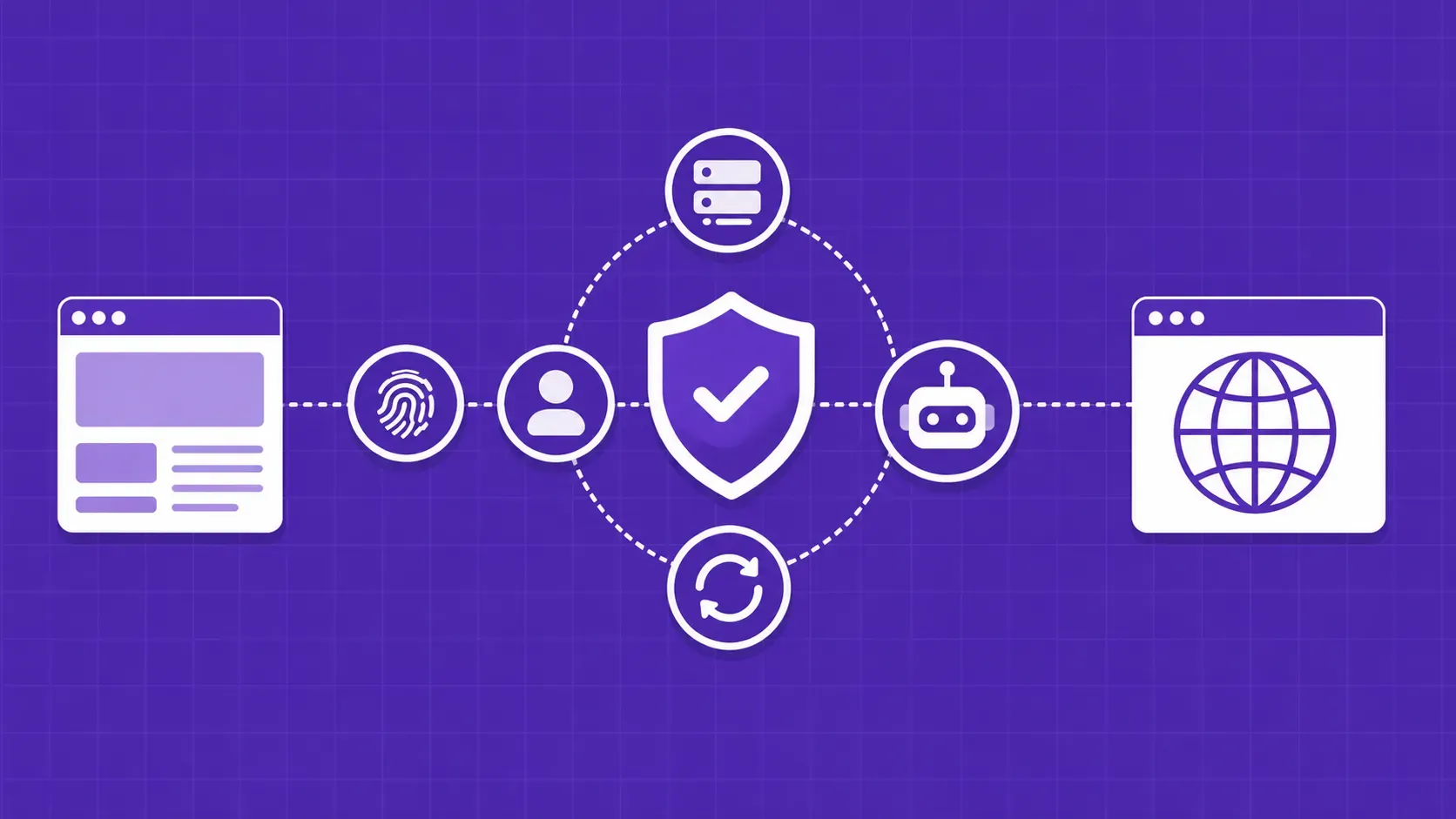
简要说明:网络搜索代理位于你的搜索器和目标网站之间,掩盖你的 IP,让你在速率限制、地理墙和反僵尸防御系统中生存。正确的类型(数据中心、住宅、ISP 或移动)和正确的协议(HTTP/HTTPS 或 SOCKS5、IPv4 或 IPv6)取决于目标网站的防御、你的地理需求以及每个页面的重要性。本指南介绍了如何权衡利弊,最后提供了一份供应商中立的清单。



要想发展业务,就必须做出正确的决策,而这就需要数据。与其手动操作,不如试试网络刮擦工具!

在网络搜索工具的帮助下,获取数据再简单不过了。了解有关使用 API 进行网络搜索的更多信息。

Web scraping API 是一种工具,可为您完成繁重的工作,让您更接近网络数据。了解有关最佳选项的更多信息。


简而言之:为 2026 年的网络抓取挑选合适的 JavaScript 库主要是一项匹配工作:静态 HTML 需要 HTTP 客户端和 Cheerio,JS 渲染的 SPA 需要 Playwright 或 Puppeteer,反僵尸目标需要隐身层或托管 API,而生产型抓取则需要 Crawlee。本指南为您提供了决策框架、一目了然的比较表、工作片段,以及关于何时完全停止编写 scraper 代码的真实观点。
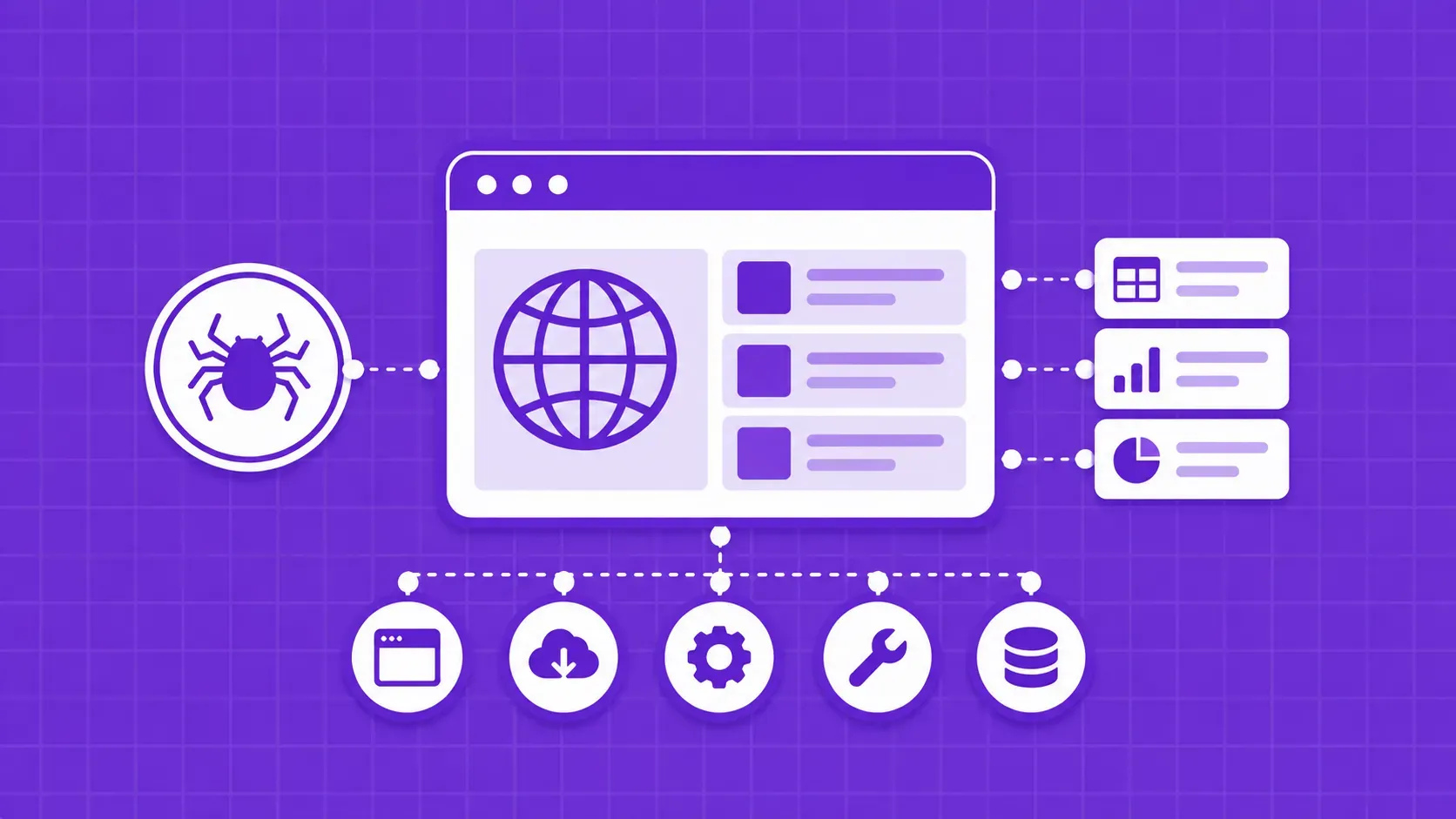
简而言之:2026 年最好的网络搜刮工具可分为三类:将代理、无头浏览器和验证码隐藏在 HTTP 调用背后的托管 API;Scrapy 和 Crawlee 等开源框架,如果你能托管它们,就能完全控制;以及面向非开发人员的无代码可视化搜刮工具。没有唯一的赢家。我们在定价模式、JavaScript 渲染、反僵尸强度和理想用例等方面比较了 22 种以上的选择,这样您就可以筛选出两到三种,与您的实际目标网站进行比较。
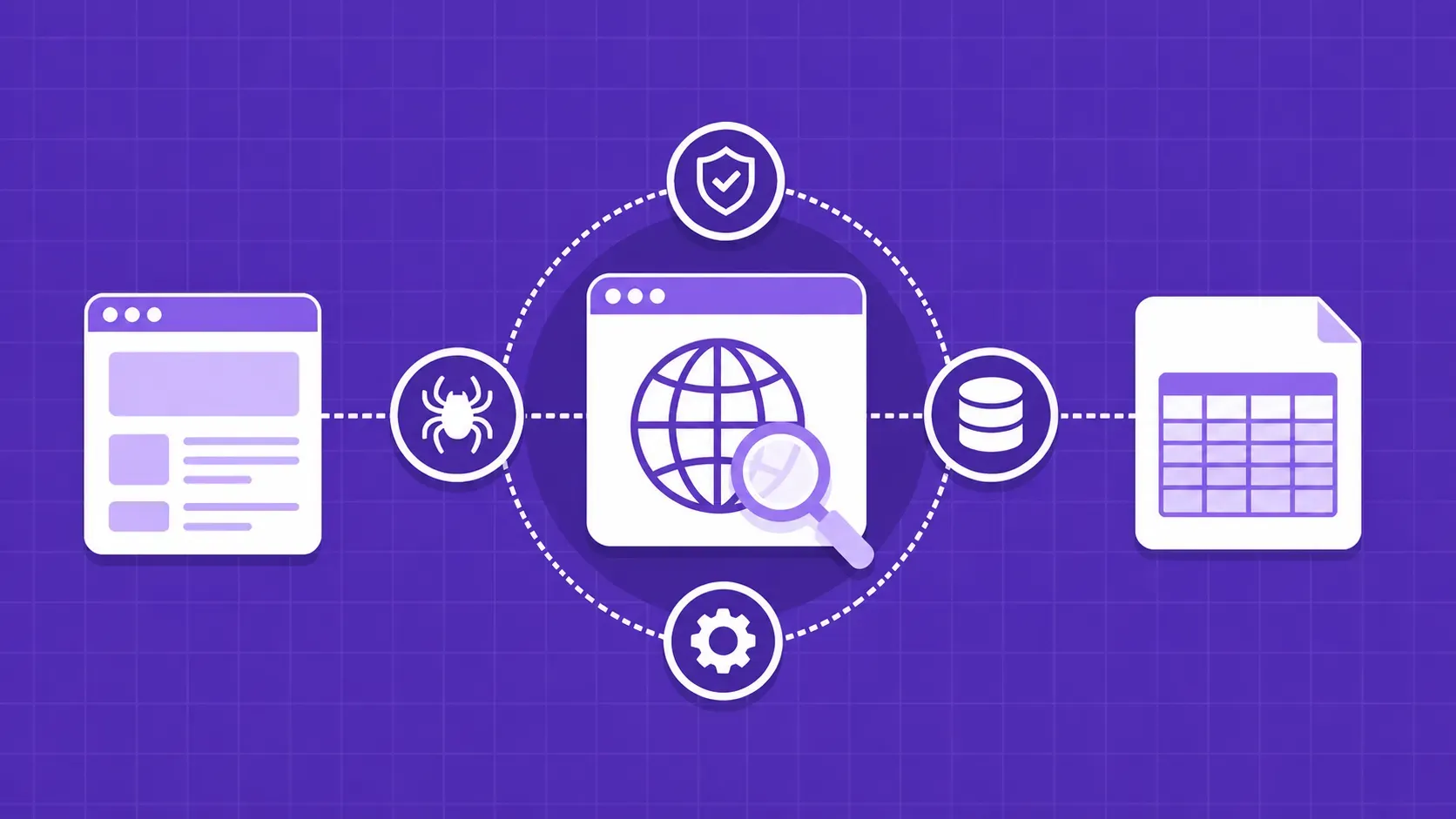
简要说明:网络搜刮是将公共网络数据自动提取为您可以实际使用的结构化格式,如 JSON 或电子表格。本指南从定义层面介绍了什么是网络刮削、网络刮削背后的请求-解析流水线、团队在哪里使用网络刮削、从无代码到可管理 API 的工具范围,以及如何在反僵尸防御和法律方面保持正确的立场。