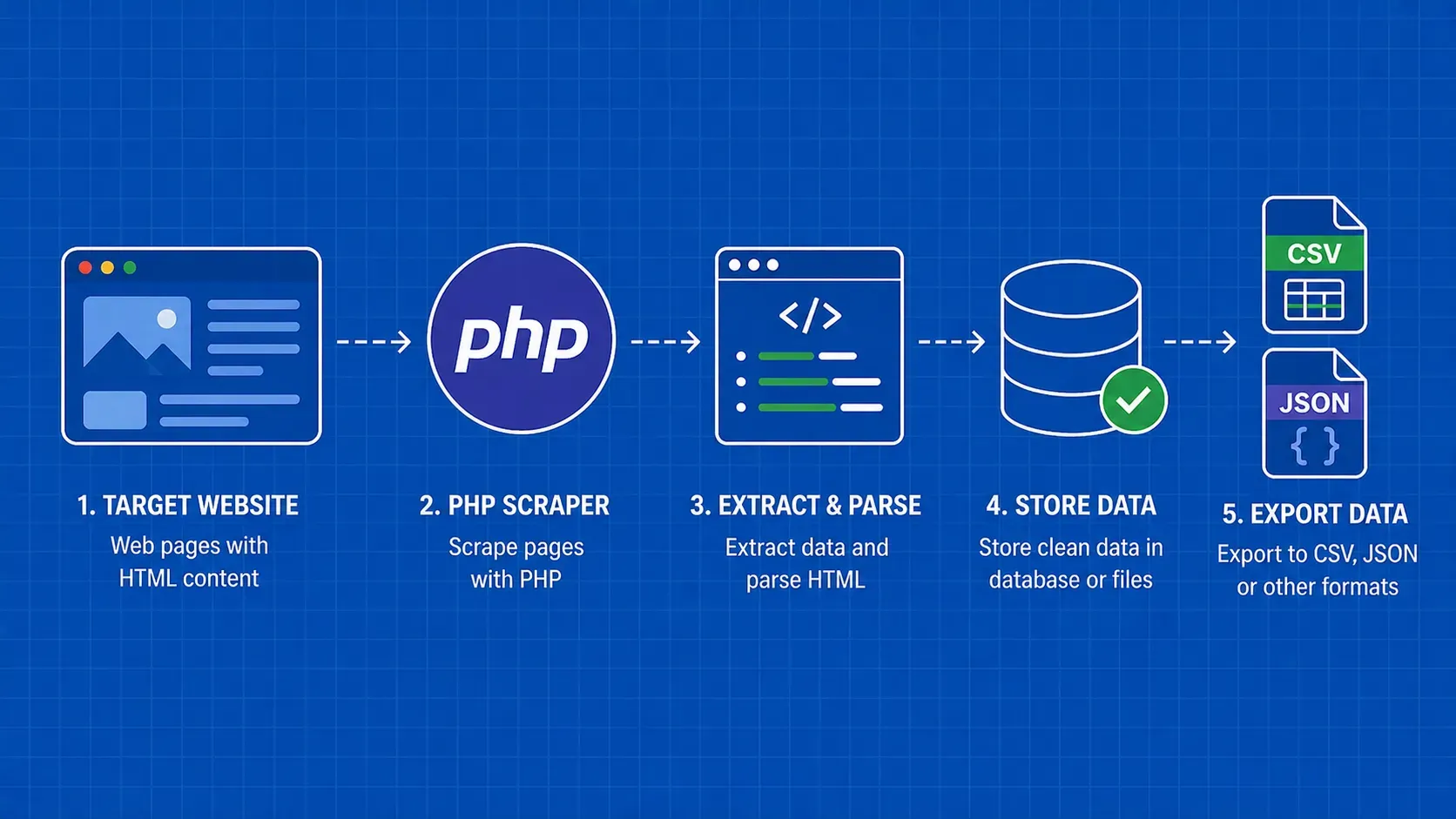
简而言之:PHP 是一门非常适合网络爬虫的语言,这得益于其内置的 cURL 和 DOMDocument 等扩展,以及包含 Guzzle、Symfony DomCrawler 和用于无头浏览的 Symfony Panther 等工具的丰富 Composer 生态系统。本指南将带您逐步了解完整的工作流程:获取页面、解析 HTML、将结果存储为 CSV/JSON/MySQL 格式、处理错误以及避免被封锁。
使用 PHP 进行网页抓取,是指通过 PHP 脚本和库,以编程方式获取网页并从其 HTML 中提取结构化数据的过程。如果您日常工作已使用 PHP 编程,那么仅为了从网站提取数据而更换语言是毫无必要的。PHP 默认自带 cURL 绑定和内置 DOM 解析器,而 Composer 则为您提供了经过实战检验的 HTTP 客户端、CSS 选择器引擎,甚至无头浏览器。
本教程面向希望获得实用、以代码为先的逐步指导的中级 PHP 开发者。您将从低级 cURL 调用开始,逐步过渡到 Guzzle 和 Symfony HttpBrowser 等高级库,使用 Symfony Panther 处理 JavaScript 渲染的页面,并最终解决数据存储、错误处理以及避免被列入封锁列表等生产环境中的问题。 本 PHP 网页抓取教程中的每个示例都贯穿于同一个场景(抓取一个公开的图书列表网站),因此您可以完整地跟随整个工作流,而不是在彼此无关的代码片段之间来回跳转。



