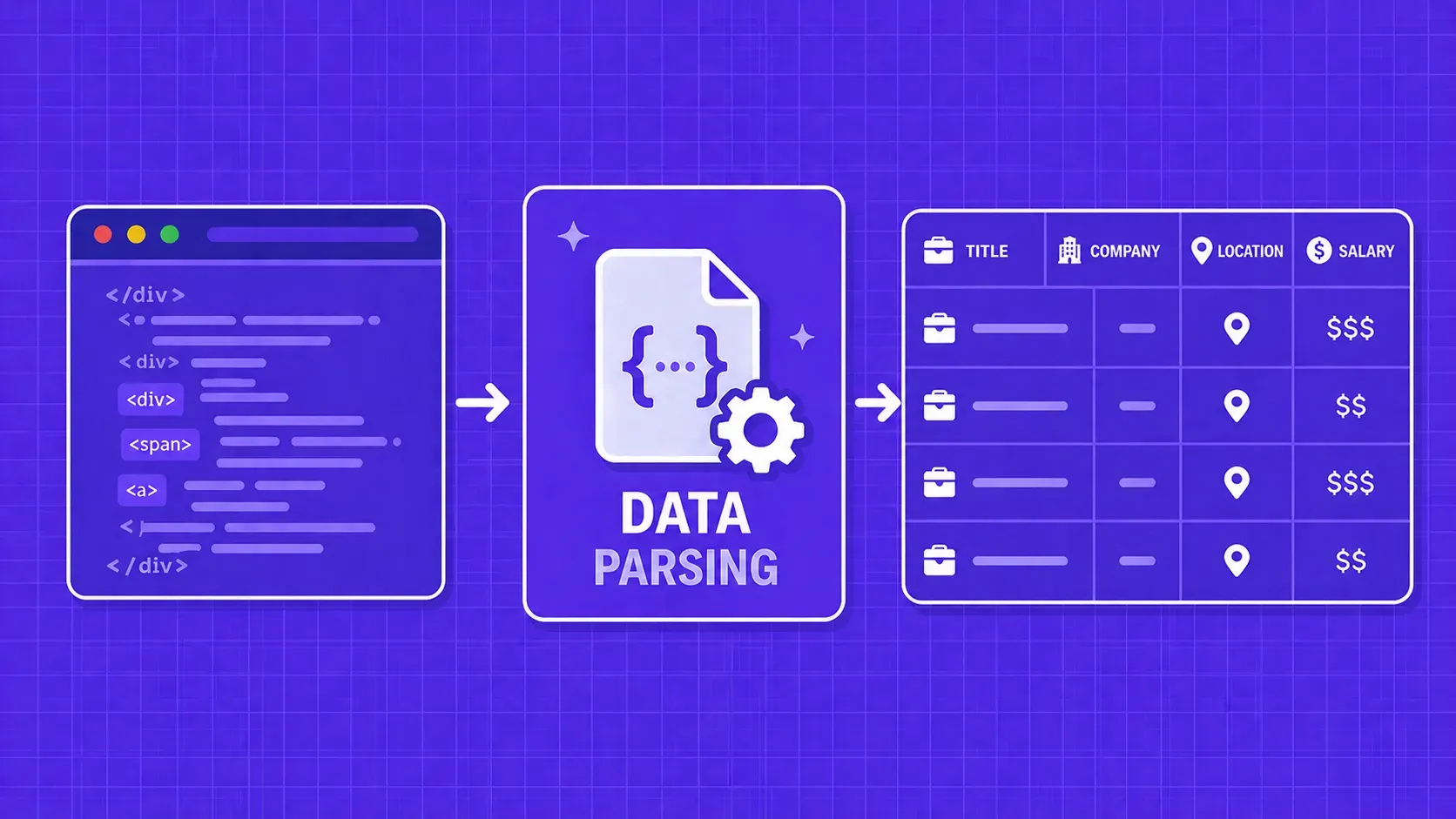
简而言之:数据解析将原始内容(HTML、JSON、XML、PDF)转换为代码可实际使用的结构化字段。本指南将逐步讲解数据解析的工作原理,对比主要技术和库,并为您提供一个实用的框架,帮助您决定是自建还是购买解析层。
每一个网络爬虫管道、ETL任务和数据集成工作流都会遇到同一个瓶颈:将原始、杂乱的内容转化为应用程序能够实际处理的形式。这个瓶颈就是数据解析——即将非结构化或半结构化输入转换为代码能够查询、存储和分析的、定义明确的结构化格式的过程。
无论您是从电商网站抓取产品价格、接收第三方 API 的 JSON 数据,还是从 PDF 报告中提取表格,解析输出的质量将直接决定后续所有环节的质量。若解析步骤出现差错,最终将导致字段缺失、管道中断,以及仪表盘中充斥着空值。
在本指南中,我们将深入探讨数据解析的底层原理,逐一解析最常见的解析技术(从正则表达式到机器学习),对比多种编程语言中的顶级解析库,并帮助您判断:针对您的具体情况,是构建自定义解析器更合适,还是采用托管解决方案更明智。



