如何使用 Colly 在 Golang 中抓取 HTML 表格:端到端指南
简要说明:本指南展示了如何在 Golang 中从头到尾地刮擦 HTML 表格:在 Colly、goquery 和 golang.org/x/net/html 之间进行选择,以正确的 <tbody> 为目标,将行建模为类型化结构,并导出干净的 JSON 和 CSV。你还能获得分页、反阻塞和 JavaScript 渲染的表格模式。
Andrei Ogiolan3 min read
May 7, 2026深入探讨网络数据基础设施、数据提取技术以及大规模结构化数据的未来。
简要说明:本指南展示了如何在 Golang 中从头到尾地刮擦 HTML 表格:在 Colly、goquery 和 golang.org/x/net/html 之间进行选择,以正确的 <tbody> 为目标,将行建模为类型化结构,并导出干净的 JSON 和 CSV。你还能获得分页、反阻塞和 JavaScript 渲染的表格模式。
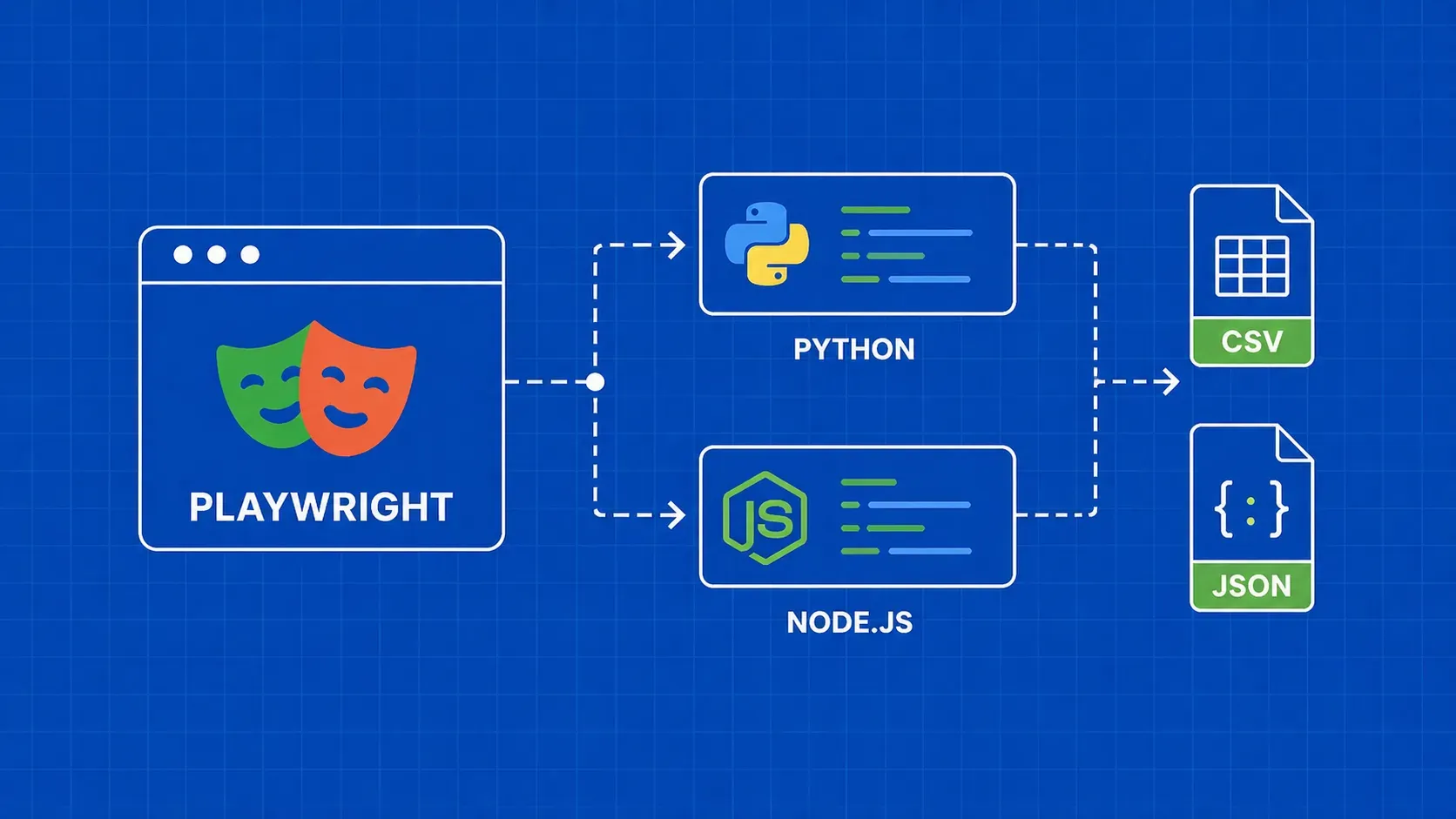
简要说明:Playwright 为您提供了全面的浏览器自动化功能,可用于刮擦 JavaScript 繁重的网站,并为 Python 和 Node.js 提供一流的支持。本指南将指导您完成安装、元素提取、代理配置、反检测、分页、图片下载以及将数据导出为 CSV 或 JSON 等操作,并提供两种语言的并行代码示例。
简要说明:要想知道如何从 Google 地图中抓取评论,有三种方法:旋转代理后的 DIY Selenium 抓取器、带有渲染说明的抓取 API 或返回解析 JSON 的结构化地图评论 API。本指南用 Python 演示了这三种方法,包括可复制粘贴的代码、分页模式、防拦截策略,以及将原始评论转化为企业可实际使用的内容的最后清理步骤。
使用 Python 和 wget 实现网页抓取和文件下载的自动化。学习如何利用这些工具收集数据并节省时间。
掌握网络爬虫技巧,避免被封禁!遵循遵守服务条款、使用代理服务器以及规避IP封禁的建议。以符合道德和法律的方式提取数据。
简要说明:本指南从头到尾介绍了如何在 Python Requests 中使用代理:一个有效的代理字典、经过验证的 URL、环境变量、会话重用、不泄漏 DNS 的 SOCKS5 以及带有重试和断路器的轮换池。到最后,你就会知道什么时候托管 API 比 DIY 池更有价值。