Ruby 网页抓取:终极教程
如果你有 Ruby、一堆实用的 gems 以及几个小时的时间,能做出什么?答案是——一个相当不错的网页爬虫。以下是分步指南:
Raluca Penciuc2 min read
Apr 22, 2026深入探讨网络数据基础设施、数据提取技术以及大规模结构化数据的未来。
如果你有 Ruby、一堆实用的 gems 以及几个小时的时间,能做出什么?答案是——一个相当不错的网页爬虫。以下是分步指南:
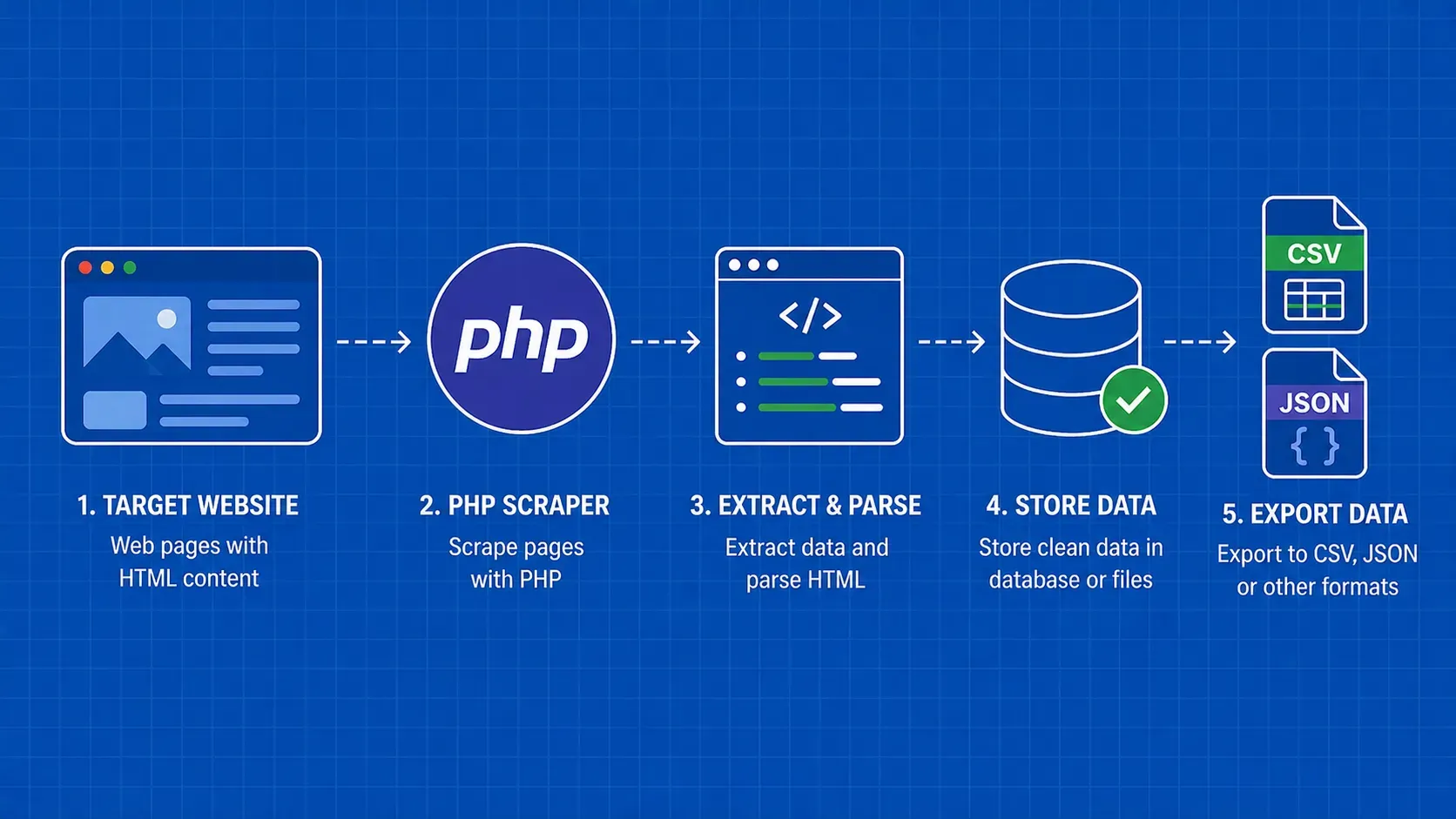
简而言之:由于内置了 cURL 和 DOMDocument 等扩展,再加上包括 Guzzle、Symfony DomCrawler 和用于无头浏览的 Symfony Panther 在内的丰富的 Composer 生态系统,PHP 完全有能力胜任 Web 搜索。本指南将指导您完成整个工作流程:获取页面、解析 HTML、将结果存储到 CSV/JSON/MySQL、处理错误以及避免阻塞。
TL;DR:那么什么是旋转代理呢?代理服务器会为来自管理池的每个请求分配不同的 IP,这就是搜刮者如何绕过每个 IP 的速率限制、验证码和地理过滤器的原因。本指南介绍了旋转的工作原理、四种池类型、三种语言的设置代码以及如何选择提供商。
简要说明:这本 XPath 小抄涵盖了网络搜刮实际需要的语法、谓词、轴和函数,还有 CSS 到 XPath 转换表和可运行的 Puppeteer 和 Scrapy 示例。下次当你依赖的网站上的 CSS 选择器悄无声息地崩溃时,你可以将它作为桌面参考。
简要说明:python 网络爬虫可以自动完成在网站上跟踪链接以发现和收集内容的繁琐工作。本指南将指导您使用请求和 BeautifulSoup 从头开始构建爬虫,然后再使用 Scrapy 进行并发爬行、项目管道和结构化数据导出。您还将学习如何负责任地抓取、旋转代理以避免阻塞,以及如何处理 JavaScript 渲染的页面。
阅读本文,了解有关代理列表的宝贵见解、代理服务器列表的优势、最佳的付费代理API工具、如何选择代理工具等更多内容。