Top 5 Best Scraping Tools For Amazon
Robert Sfichi on Apr 20 2021

Web scraping is the process of fetching a web page and extracting the data found on it. Once you have the information, you’ll typically want to parse, analyze, reformat or copy it into a spreadsheet.
Web scraping has plenty of uses, but today we’ll focus on just a few: gathering price and product data from marketplaces. Retailers use this knowledge to understand the market and their competition better.
The advantages can be pretty huge, in fact. Think about it: to counter your competition’s strategy, you have to first know it. By knowing their prices, for example, you can get a leg up on sales with a special discount, or by selling at a lower cost.
Amazon represents one of the largest marketplaces on the Internet. People use its services on a daily basis to order groceries, books, laptops, and even web hosting services. In the future, Amazon plans to add fully built houses to this list.
As a top eCommerce site, Amazon is one of the biggest databases for products, reviews, retailers, and market trends. It’s a web scraping gold mine.
We are going to analyze the best 5 APIs to scrape Amazon data without getting blocked. If you’re trying to find the best tool to extract data from Amazon, this article will save you a lot of time.
Let’s begin! Click on any one of the following services to jump to its section.
Why would anyone scrape Amazon data?
If you have ever tried to sell anything online you know that some of the most important steps in this process are:
- competitor analysis;
- improving your products and value proposition;
- identifying market trends and what influences them.
By scraping amazon data, we can easily get, compare and monitor competing product information, like price, reviews, or availability. We can analyze the cost management for their operations but also find great deals for reselling.
One thing is certain. If you use Amazon to sell your products, you will benefit from analyzing all the previously presented factors. You can do it by yourself, manually watching over hundreds or even thousands of products, or you can use a tool to automate it.
In the following paragraphs, we are going to try to offer a couple of solutions for anyone who is having a hard time scraping Amazon information.
Why do you need a web scraping API?
Amazon represents one of the largest (if not the largest) shops the Internet has ever seen. As such, Amazon is also one of the biggest collections of data regarding customers, products, reviews, retailers, market trends, and even customer temperament.
Before we start discussing data extraction, you should know that Amazon does not encourage scraping its website. This is why the structure of the pages differs if the products fall into different categories. The website includes some basic anti-scraping measures that could prevent you from getting your much-needed information. Besides this, Amazon can find out if you’re using a bot to scrape it and will definitely block your IP.
Best scraping APIs for the job
In order to get the job done as fast as possible and without creating a new project for each tool we are going to test, we are going to do the scraping using a terminal and some curl requests. We have chosen five promising web scraping APIs to try out.
Let’s take each one of them for a test and find out which is the best tool to scrape Amazon data:
1. WebScrapingAPI
WebScrapingAPI is a tool that allows us to scrape any online resource. It collects the HTML from any web page using a simple API and it provides ready to process data. It’s great for extracting product information, processing real estate, HR, or financial data, and even tracking information for a specific market. Using WebScrapingAPI, we can get all the information needed from a specific Amazon product page.
First, let’s find an interesting product on the Amazon marketplace.
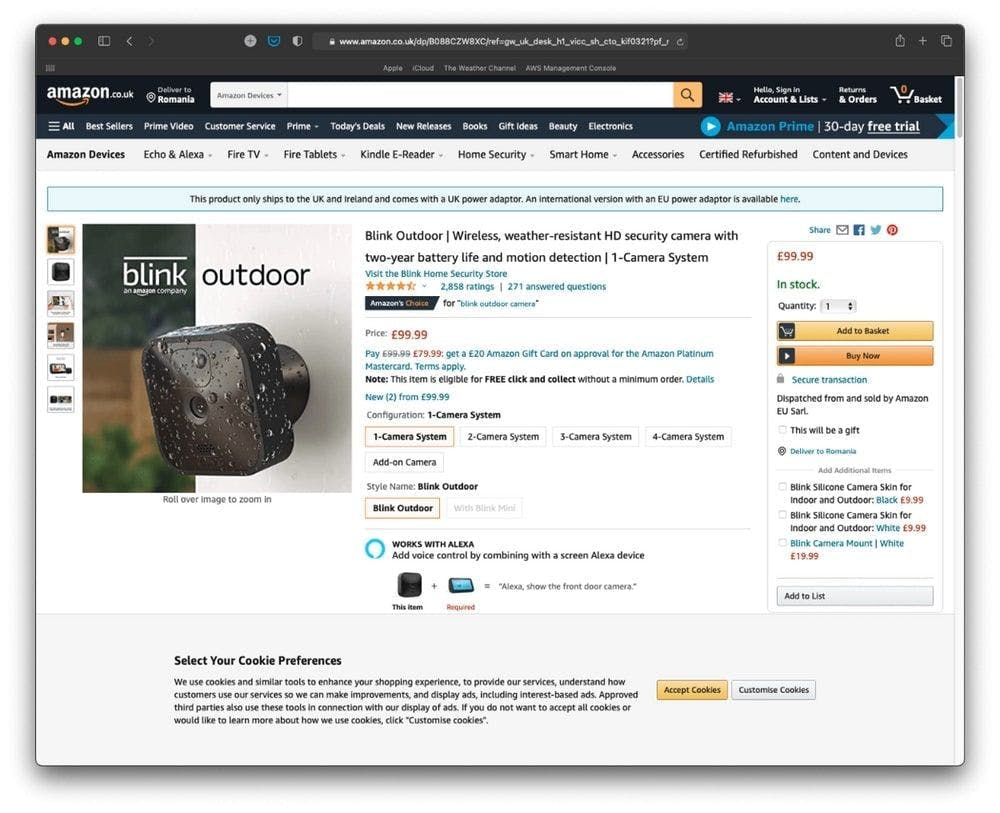
We’re going to scrape the product page presented in the image above.
Secondly, let’s get the product’s page URL: https://www.amazon.co.uk/dp/B088CZW8XC/ref=gw_uk_desk_h1_vicc_sh_cto_kif0321?pf_rd_r=RYXBGN8C757Y9BD6W38B
After we create a new WebScrapingAPI account, we are going to be redirected towards the application’s dashboard. WebScrapingAPI offers a free plan with 1000 requests to test the application. That is more than enough for what we are going to do.
From the dashboard page, we are going to click on the “Use API Playground” button. Here we can see the full curl command that will help us scrape the Amazon product page.
Let’s paste the product’s link in the URL input. This will change the preview of the URL command on the right.
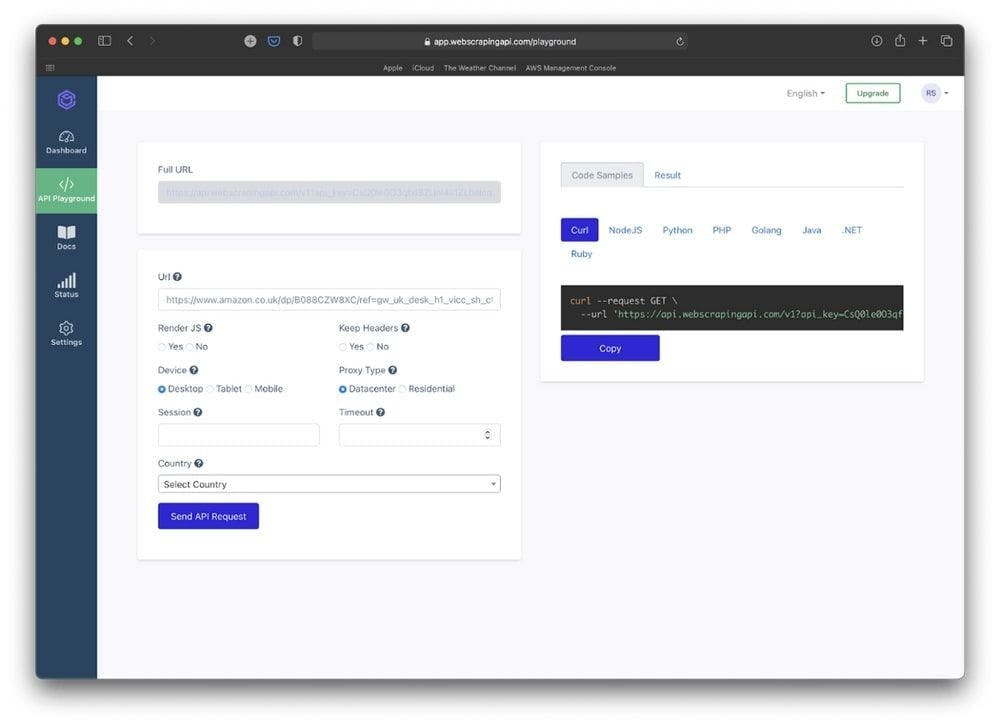
After this step is completed, copy the curl command, open a new terminal window and paste it right there. If you followed the previous steps, you should get something like this:
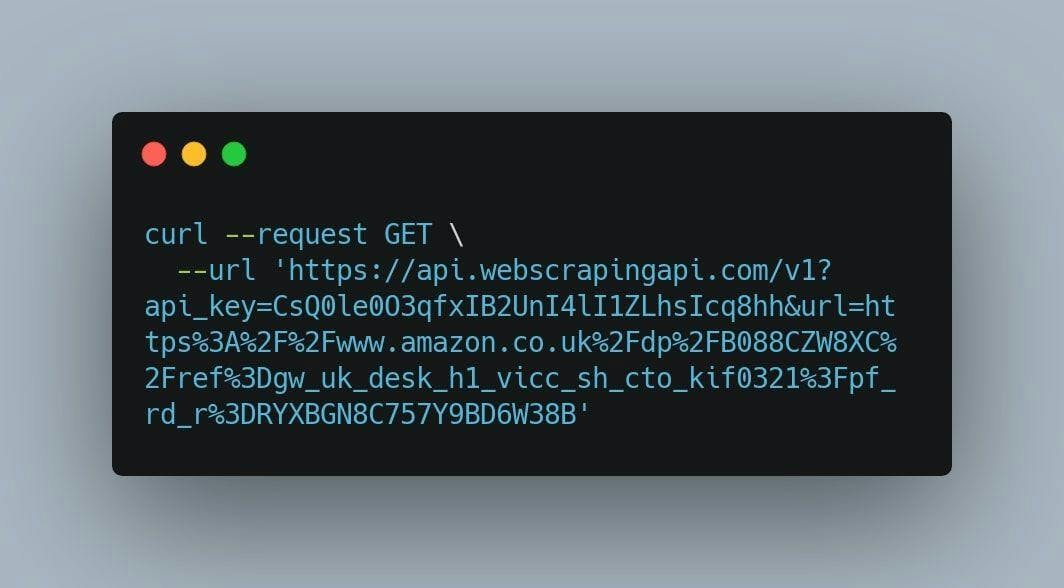
After we hit enter, WebScrapingAPI is going to return the product’s page in HTML format.
From our research, WebScrapingAPI managed to successfully get the information needed in 99.7% of the cases with a success rate of 997 out of 1000 requests and just 1-second latency.
2. ScrapingBee
ScrapingBee offers the opportunity to web scrape without getting blocked, using both classic and premium proxies. It focuses on extracting any data you need rendering web pages inside a real browser (Chrome). Thanks to their large proxy pool, developers and companies can scrape without worrying about proxies and headless browsers.
Let’s try to scrape the same Amazon page as we did before. Create a new account on ScrapingBee, go to the application’s dashboard, and paste the previously presented URL in the URL input.
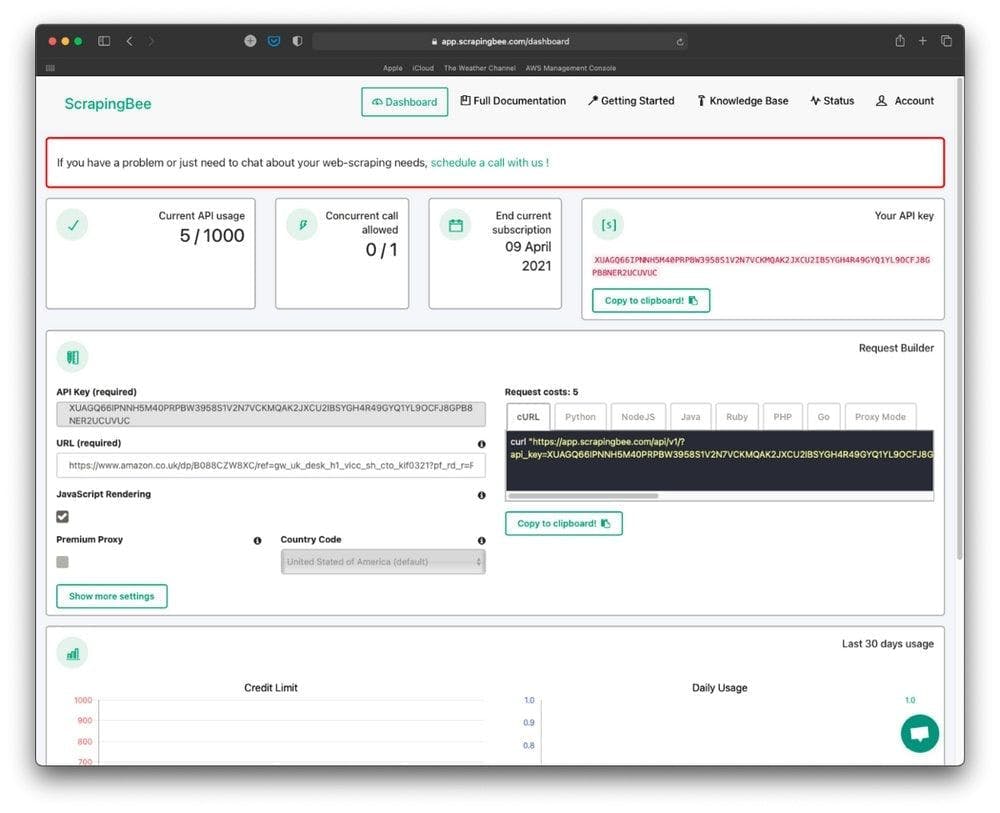
Click on the “Copy to clipboard” button that can be found in the “Request Builder” section.
Now, let’s open a terminal window, paste the code we have just copied, and hit ENTER.
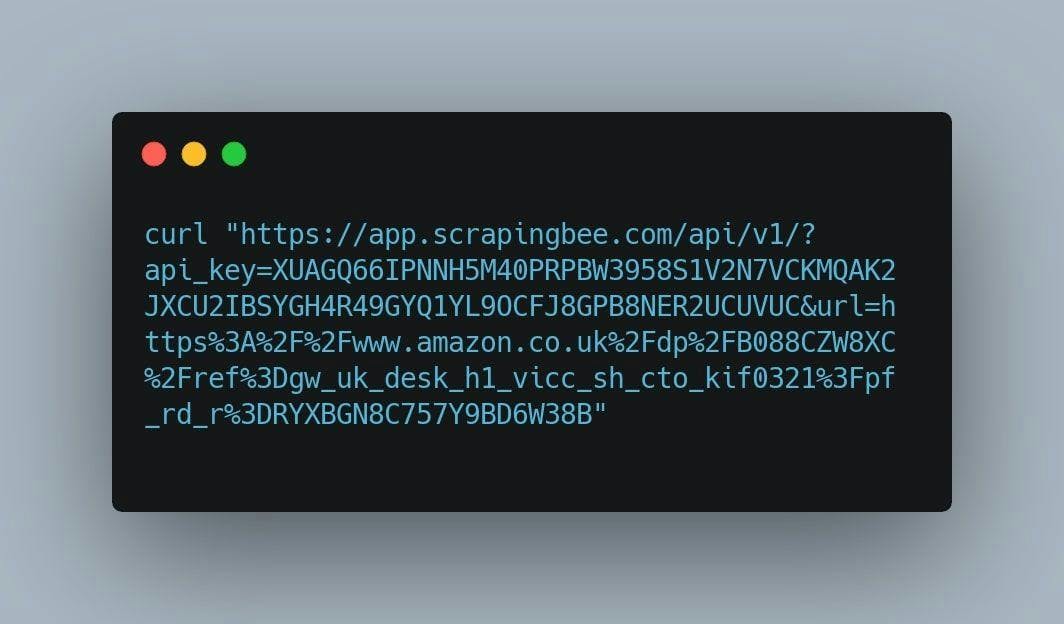
By running this command, we are going to scrape the same page on the Amazon marketplace, so we can compare the results each API gets.
From our research, we have found out that ScrapingBee managed to get the information successfully in 92.5% of the cases and a pretty big latency of 6 seconds.
3. ScraperAPI
ScraperAPI is a tool for developers building web scrapers — as they say — the tool that scrapes any page with a simple API call. The web service handles proxies, browsers, and CAPTCHAs so that developers can get the raw HTML from any website. Moreover, the product manages to find a unique balance between its functionalities, reliability, and ease of use.
Just as we did before, we’re going to create a new account on ScraperAPI and use their 1000 free requests to test their scraping tool. After we’ve completed the registration process, we’re going to be redirected to the following page:
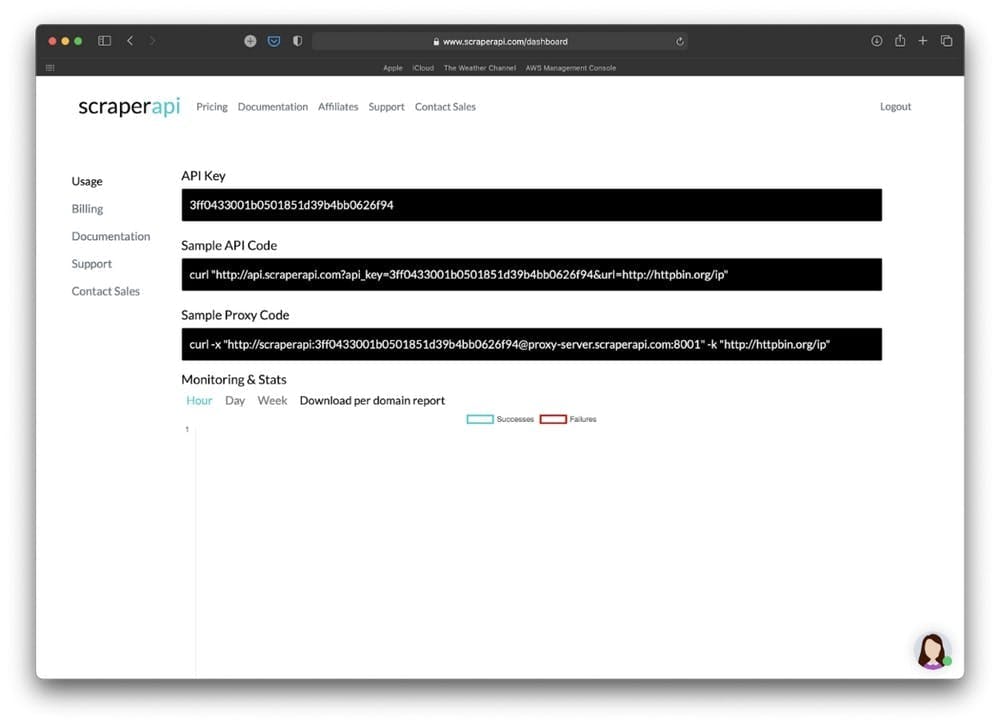
At first glance, ScraperAPI doesn’t look like it offers the option of customizing the curl request by writing a new URL. That’s not a big deal. We’re going to open a new terminal window and copy the code from the “Sample API Code” input.
As we can see, the default URL that it’s being scraped is “http:/httpbin.org/ip”. We are going to change it to the escaped version of the product’s page URL presented at the top of the section. Change the previously presented link with the following one:
https%3A%2F%2Fwww.amazon.co.uk%2Fdp%2FB088CZW8XC%2Fref%3Dgw_uk_desk_h1_vicc_sh_cto_kif0321%3Fpf_rd_r%3DRYXBGN8C757Y9BD6W38B
The final command should look something like this:
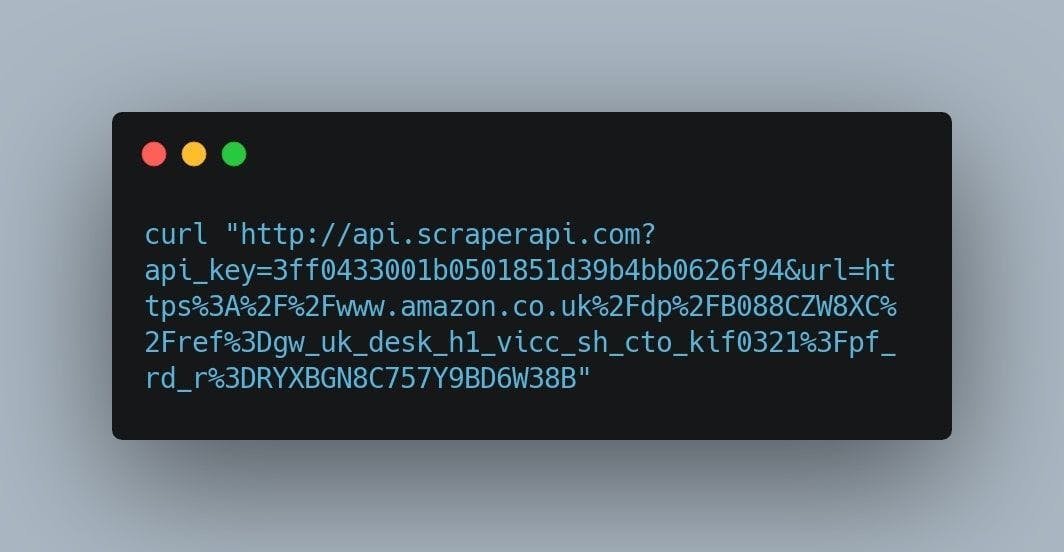
After we hit enter, we will be presented with the HTML code of the product’s page. You can, of course, use Cheerio or any other markup parser in order to manipulate the resulting data structure.
ScraperAPI seems to be one of the best choices as its success rate is 100% and the latency does not exceed 1 second.
As we’ve stated in the previous chapter, keep in mind that Amazon discourages any attempts at scraping their website data.
4. Zenscrape
Zenscrape is a web scraping API that returns the HTML of any website and ensures developers collect information fast and efficiently. The tool allows you to harvest online content smoothly and reliably by solving Javascript rendering or CHAPTCHAs.
Just as we did before, after we complete the registration process, we’re going to be redirected to the dashboard page.
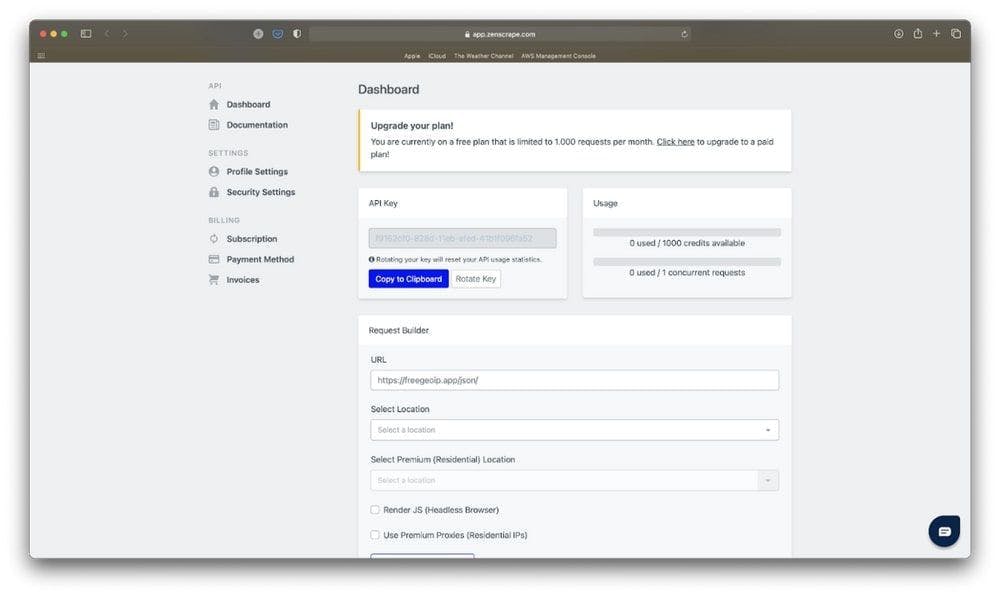
Let’s copy and paste the product’s page URL in the URL input.
In order to reveal the curl command we need for scraping the Amazon data, we will scroll down to the middle of the page. Click on the “Copy to Clipboard” button, open a new terminal window and paste it. It should look similar to this:
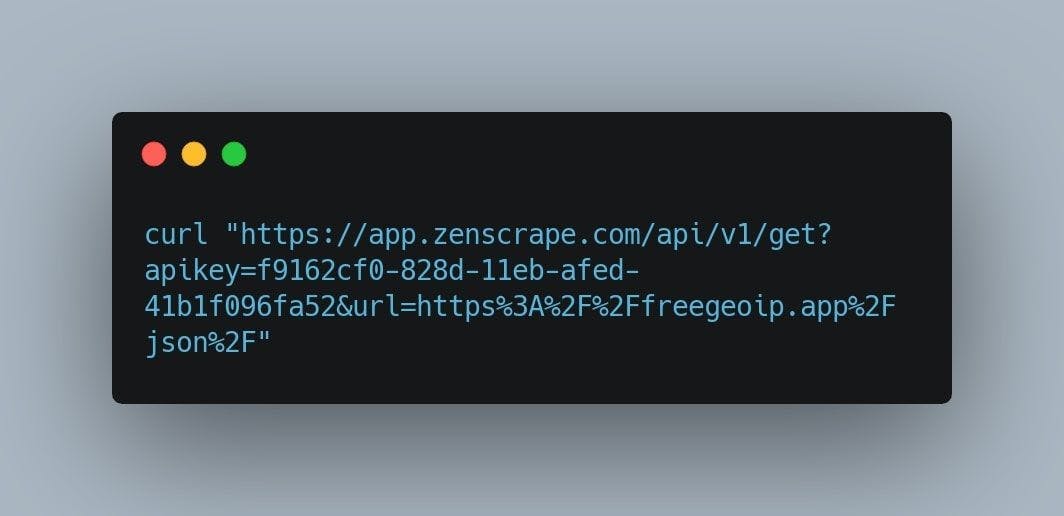
Just like with the other web scraping tools, the result we’re going to get will be the page structured in HTML format.
From our research, we found out Zenscrape has a success rate of 98% with 98 successful requests out of 100 and a latency of 1.4 seconds. This ranks it lower than the previously presented tools, but in our opinion, it has one of the most intuitive and beautiful user interfaces and it definitely gets the job done.
5. ScrapingAnt
ScrapingAnt is the scraping tool that provides its customers a full web harvesting and scraping experience. It is a service that handles Javascript rendering, headless browser updates and maintenance, proxies diversity, and rotation. The scraping API offers high availability, reliability, and customization of features to fit any business needs.
For our final test, we are going to repeat the same process. Let’s create a new account on ScrapingAnt and use their 1000 free requests to scrape the Amazon product’s page.
I think we got pretty familiar with the web scraper interfaces.
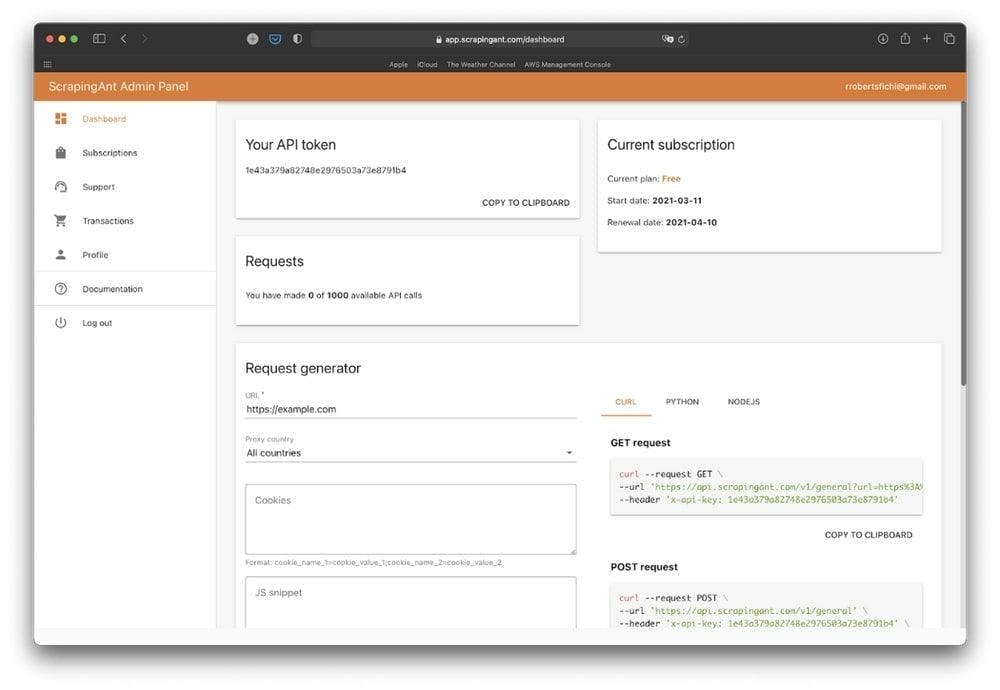
Just as we did before, replace the URL input value with our URL, copy the curl command to a new terminal window, and hit ENTER.
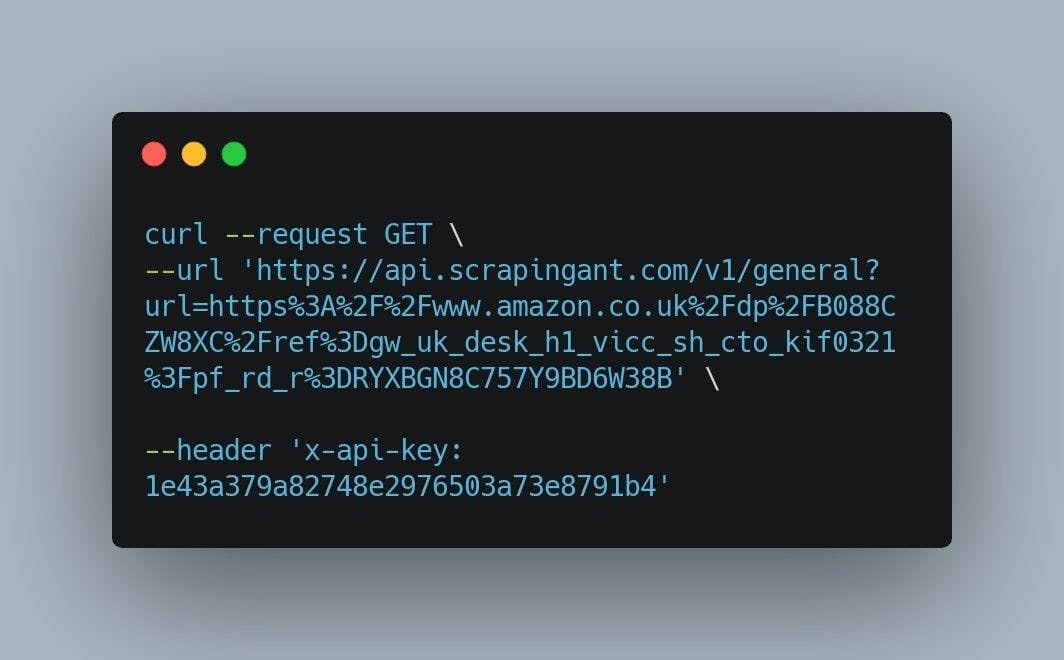
This will return a similar HTML structure which we can then parse by using Cheerio or any other markup parser. ScrapingAnt’s key features are Chrome page rendering, output preprocessing, and scraping requests with a low chance of CAPTCHA check triggering.
From our research, we have found out ScrapingAnt has a request success rate of 100% with a latency of 3 full seconds. Although its success rate is one of the highest in this list, the 3 seconds latency presents a big issue when we’re scraping a lot of Amazon product data.
Conclusion
As we have seen, the process it’s pretty much the same for all the web scraping APIs. You find a page to scrape, write the curl request including the product’s link, make the request and based on your personal needs, parse the received data.
In this process, we tried to determine what is the best tool for the job. We managed to test and analyze 5 scrapers and found out the results are not that different. In the end, they all get the job done. The difference is made by each scraper’s latency, success rate, number of free requests, and pricing.
WebScrapingAPI is a great solution when it comes to scraping Amazon data as it has one of the smallest latencies (1 second) and a success rate close to 100%. It includes a free tier for those of us who don’t need to make a large number of requests and it also comes with 1000 free requests if you just feel like testing it out.
ScrapingBee is the second web scraper we have tested but the results were not so satisfying. With a success rate of only 92.5% and a pretty big latency (6 seconds), we would have a challenging time trying to get the information needed about our Amazon product.
ScraperAPI is also one of the fastest scrapers we have tested. With only 1-second latency and a 100% success rate, it has the best results when it comes to technical requirements. Its downside is the user interface, as it seems to be like the most rudimental one. The pricing model is another weak point, as it does not provide any free tier.
Zenscrape definitely has one of the most intuitive user interfaces of all of the scrapers we have tested. The only one that gets close is WebScrapingAPI. Zenscrape has a latency of just 1.4 seconds and a success rate of 98%.
ScrapingAnt is the last scraper we have tested. With a latency of approximately 3 seconds and a success rate of 100%, it’s a good choice for scraping the Amazon information we need, but a bit slow.
In the end, all the web scrapers we have tested do a very good job when it comes to scraping Amazon product data. Although the scoreboard is pretty tight, we should always choose the most efficient tool for our specific requirements.
We recommend you try them yourselves. See which product is the best fit for your needs. Also, check out this article on how to use a web scraping API to its full extent. After all, picking a tool and knowing how to utilize it is not the same thing.
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Are XPath selectors better than CSS selectors for web scraping? Learn about each method's strengths and limitations and make the right choice for your project!


Learn how to use proxies with Axios & Node.js for efficient web scraping. Tips, code samples & the benefits of using WebScrapingAPI included.


Understanding the difference between two different DAO models for decentralization, we are reviewing simmilar but toatally different neworks ice and Pi.
